
用好 AI:Claude 帮我完成 Memos SQLite 到 MySQL 的数据库迁移
详解展示了使用 Claude 3.5 Sonnet 进行 prompt tuning 的过程,借助 AI 在半小时内完成将 memos service 的数据库由 SQLite 迁移到阿里云 MySQL RDS

近期阿里云双十一活动 RDS 99/年,非常有性价比,于是我就买了一个香港区的 MySQL RDS 用做我的 Memos 数据服务。这就不可避免的碰到了数据库迁移的问题,即需要将 SQLite 数据库迁移到 MySQL,这种生产环境的数据库迁移一般都非常谨慎,需要严格 SQL 开发和验证,需要花费不少的时间。由于 SQLite 文件有备份,刚刚购买的 MySQL 资源充足,心血来潮之下想玩一波大的 —— 试试 AI 来帮我完成生产数据库的迁移工作。
我完成这些事情是 prompt tune 的思路,主要包括:
- 找到当前版本 memos 的库表创建的 sql 文件;
- 创建测试用的本地 mysql 数据库服务;
- prompt 进行提示词问询,生成 python 迁移工具;
- 执行迁移测试,收集脚本报错以及数据库表问题;
- 根据测试发现的问题,进行 prompt tuning,生成新的 python 迁移工具;
- 根据第1步的 sql 文件完成库表创建,然后执行 python 迁移工具完成生产数据库的迁移;
前期准备
查找库表创建 SQL 文件
这里主要是确认当前生产数据创建了哪些库表,有两种方法:
- 去 SQLite 数据库文件中通过 SQL 命令查询:
show create table ${table name} - 去 memos sql 文件中查找,edonyzpc/memos/store/migration/sqlite/prod/LATEST.sql(如果非自定义镜像可以去 usememos 查找
本地 mysql 测试环境
1. 准备 init.sql 文件
CREATE DATABASE IF NOT EXISTS memos-migrate-test;
2. 准备 docker compose 文件
version: '3'
services:
db:
image: mysql:latest
ports:
- 3306:3306
restart: always
environment:
MYSQL_ROOT_PASSWORD: your_root_password
volumes:
- ./data:/var/lib/mysql
- ./init.sql:/docker-entrypoint-initdb.d/init.sql
3. 启动本地测试 mysql
docker pull mysql
docker compose up -d
prompt 初始化
I have a notes service and the data is stored on sqlite database, now i want to migrate all the data to mysql, please help me to write a script in python. Here is the schema definition of the sqlite database
<<<LATEST.sql>>>
注意:替换 LATEST.sql 的内容。
Prompt Tuning
当前具备 code 分析能力的 LLM 均可以用来做迁移工具的 prompt tune,由于 Claude 在代码分析和生成等领域有非常不错的口碑,所以我这次使用了 Claude 3.5 Sonnet 作为调优模型。
1. 初始化 prompt
Here's a Python script that can help you migrate data from SQLite to MySQL based on the schema you provided:
\`\`\`python
import sqlite3
import mysql.connector
import json
# SQLite connection
sqlite_conn = sqlite3.connect('path_to_your_sqlite_database.db')
sqlite_cursor = sqlite_conn.cursor()
# MySQL connection
mysql_conn = mysql.connector.connect(
host="your_mysql_host",
user="your_mysql_user",
password="your_mysql_password",
database="your_mysql_database"
)
mysql_cursor = mysql_conn.cursor()
# List of tables to migrate
tables = [
"migration_history", "system_setting", "user", "user_setting", "memo",
"memo_organizer", "memo_relation", "resource", "activity", "idp",
"inbox", "webhook", "reaction"
]
for table in tables:
print(f"Migrating table: {table}")
# Fetch data from SQLite
sqlite_cursor.execute(f"SELECT * FROM {table}")
rows = sqlite_cursor.fetchall()
if not rows:
print(f"No data in table {table}")
continue
# Get column names
columns = [description[0] for description in sqlite_cursor.description]
# Prepare MySQL insert query
placeholders = ', '.join(['%s'] * len(columns))
columns_string = ', '.join(columns)
insert_query = f"INSERT INTO {table} ({columns_string}) VALUES ({placeholders})"
# Insert data into MySQL
for row in rows:
# Convert any JSON fields
processed_row = []
for value, column in zip(row, columns):
if column in ['tags', 'payload']:
try:
processed_value = json.dumps(json.loads(value))
except:
processed_value = value
else:
processed_value = value
processed_row.append(processed_value)
try:
mysql_cursor.execute(insert_query, processed_row)
except mysql.connector.Error as err:
print(f"Error inserting into {table}: {err}")
continue
mysql_conn.commit()
print(f"Migrated {len(rows)} rows for table {table}")
# Close connections
sqlite_conn.close()
mysql_conn.close()
print("Migration completed")
\`\`\`
Before running this script, make sure to:
1. Install required packages: `pip install mysql-connector-python`
2. Replace `'path_to_your_sqlite_database.db'` with the actual path to your SQLite database file.
3. Update the MySQL connection details (host, user, password, database) with your actual MySQL server information.
This script does the following:
1. Connects to both SQLite and MySQL databases.
2. Iterates through each table in the given list.
3. Fetches all data from the SQLite table.
4. Prepares an insert query for MySQL.
5. Inserts the data into the corresponding MySQL table, handling JSON fields if necessary.
6. Commits the changes and moves to the next table.
Note that this script assumes that you have already created the tables in MySQL with the same schema as in SQLite. If you haven't, you'll need to create the tables in MySQL first using the CREATE TABLE statements you provided.
Also, be aware that this script does not handle auto-increment fields specially. If you have auto-increment fields and want to preserve the exact IDs from SQLite, you may need to modify the script to handle this (e.g., by temporarily disabling auto-increment in MySQL during the migration).
2. prompt tuning
prompt tuning 就是在测试环境中执行 Claude 生成的工具,并将测试的报错内容反馈给 Claude 让它继续进行优化调整,并重新生成迁移工具。
库表没有创建
测试初始化 prompt 步骤中的迁移工具,发现有如下报错:
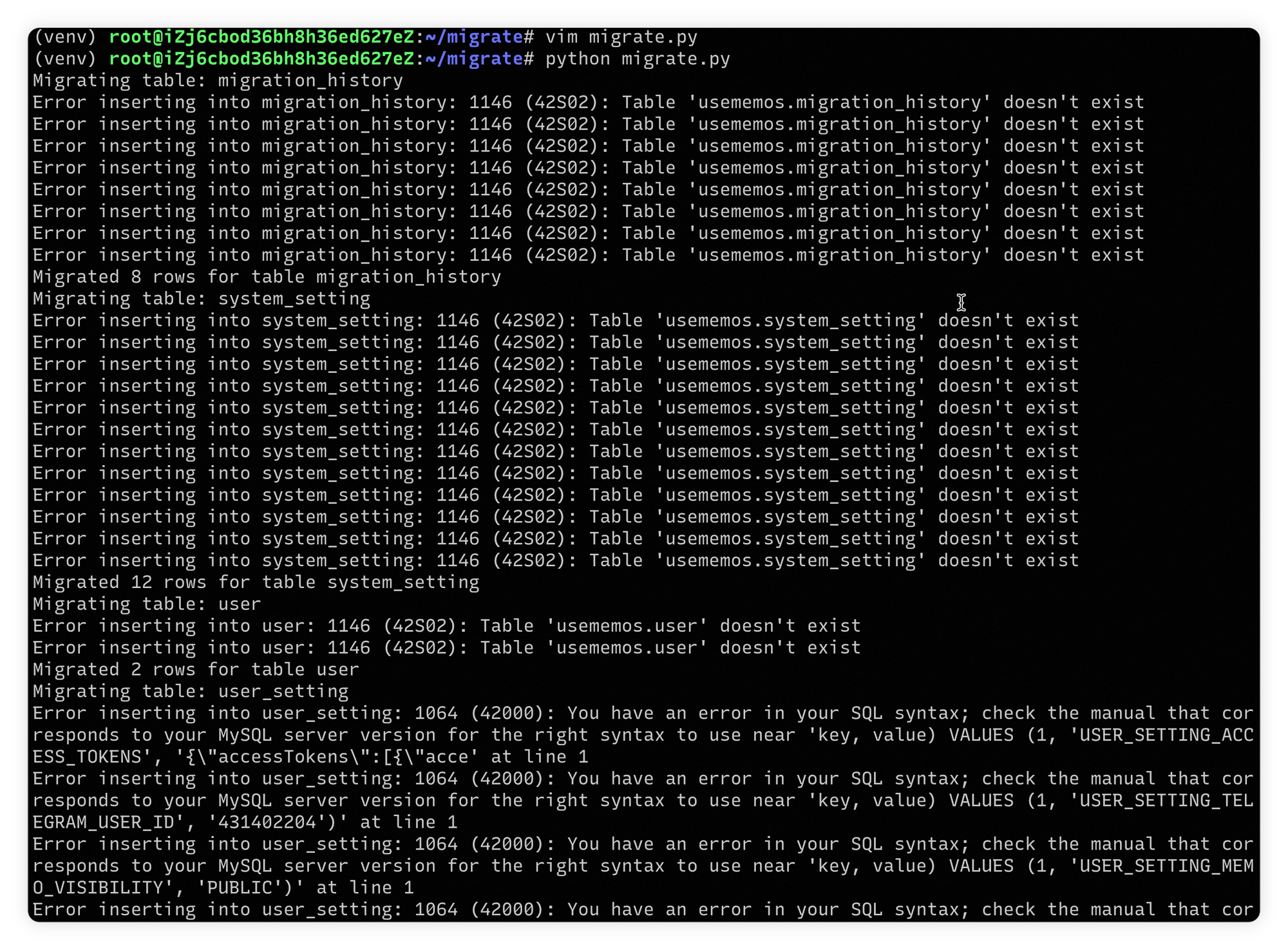
- prompt tuning: 这一步不需要 prompt 优化,只需要在测试的 MySQL 中执行建表语句,完成库表的创建(
LATEST.sql)
时间戳表列类型不对
进行测试发现有时间戳相关报错:
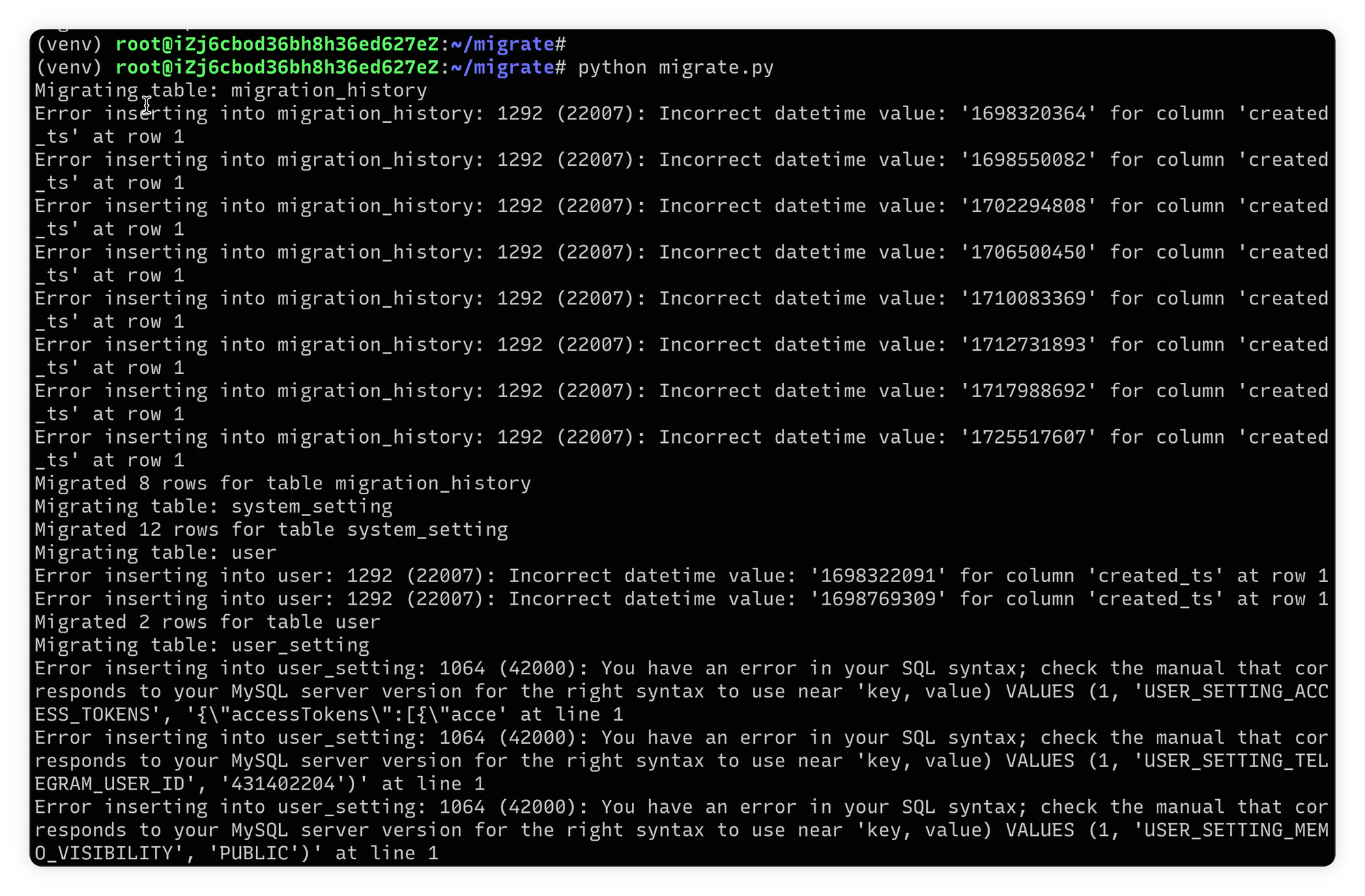
- prompt tuning:
migrate error: Incorrect datetime value: '1698320364' for column 'created_ts' - prompt result:
I apologize for the oversight. The error you're encountering is due to a difference in how SQLite and MySQL handle datetime values. SQLite often stores timestamps as Unix timestamps (seconds since epoch), while MySQL expects a formatted datetime string.
To resolve this issue, we need to convert the Unix timestamp to a datetime format that MySQL can understand. Here's an updated version of the script that handles this conversion:
\`\`\`python
import sqlite3
import mysql.connector
import json
from datetime import datetime
# SQLite connection
sqlite_conn = sqlite3.connect('path_to_your_sqlite_database.db')
sqlite_cursor = sqlite_conn.cursor()
# MySQL connection
mysql_conn = mysql.connector.connect(
host="your_mysql_host",
user="your_mysql_user",
password="your_mysql_password",
database="your_mysql_database"
)
mysql_cursor = mysql_conn.cursor()
# List of tables to migrate
tables = [
"migration_history", "system_setting", "user", "user_setting", "memo",
"memo_organizer", "memo_relation", "resource", "activity", "idp",
"inbox", "webhook", "reaction"
]
# List of timestamp columns
timestamp_columns = ['created_ts', 'updated_ts']
def convert_timestamp(value):
try:
return datetime.fromtimestamp(int(value)).strftime('%Y-%m-%d %H:%M:%S')
except ValueError:
return value
for table in tables:
print(f"Migrating table: {table}")
# Fetch data from SQLite
sqlite_cursor.execute(f"SELECT * FROM {table}")
rows = sqlite_cursor.fetchall()
if not rows:
print(f"No data in table {table}")
continue
# Get column names
columns = [description[0] for description in sqlite_cursor.description]
# Prepare MySQL insert query
placeholders = ', '.join(['%s'] * len(columns))
columns_string = ', '.join(columns)
insert_query = f"INSERT INTO {table} ({columns_string}) VALUES ({placeholders})"
# Insert data into MySQL
for row in rows:
# Convert any JSON fields and timestamps
processed_row = []
for value, column in zip(row, columns):
if column in ['tags', 'payload']:
try:
processed_value = json.dumps(json.loads(value))
except:
processed_value = value
elif column in timestamp_columns:
processed_value = convert_timestamp(value)
else:
processed_value = value
processed_row.append(processed_value)
try:
mysql_cursor.execute(insert_query, processed_row)
except mysql.connector.Error as err:
print(f"Error inserting into {table}: {err}")
continue
mysql_conn.commit()
print(f"Migrated {len(rows)} rows for table {table}")
# Close connections
sqlite_conn.close()
mysql_conn.close()
print("Migration completed")
\`\`\`
The main changes in this updated script are:
1. We've added a list of `timestamp_columns` that need to be converted.
2. We've added a `convert_timestamp` function that converts Unix timestamps to MySQL datetime format.
3. In the data processing loop, we now check if a column is in the `timestamp_columns` list and convert it if necessary.
This script should handle the timestamp conversion correctly. If you encounter any other issues or if some tables have different datetime formats, you may need to adjust the `convert_timestamp` function or add more specific handling for certain tables or columns.
Also, make sure that your MySQL tables are set up to accept NULL values for timestamp columns if applicable, as some of your SQLite data might contain NULL values for these fields.
关键字语法错误
再次进行测试发现有保留关键字导致语法相关的报错:
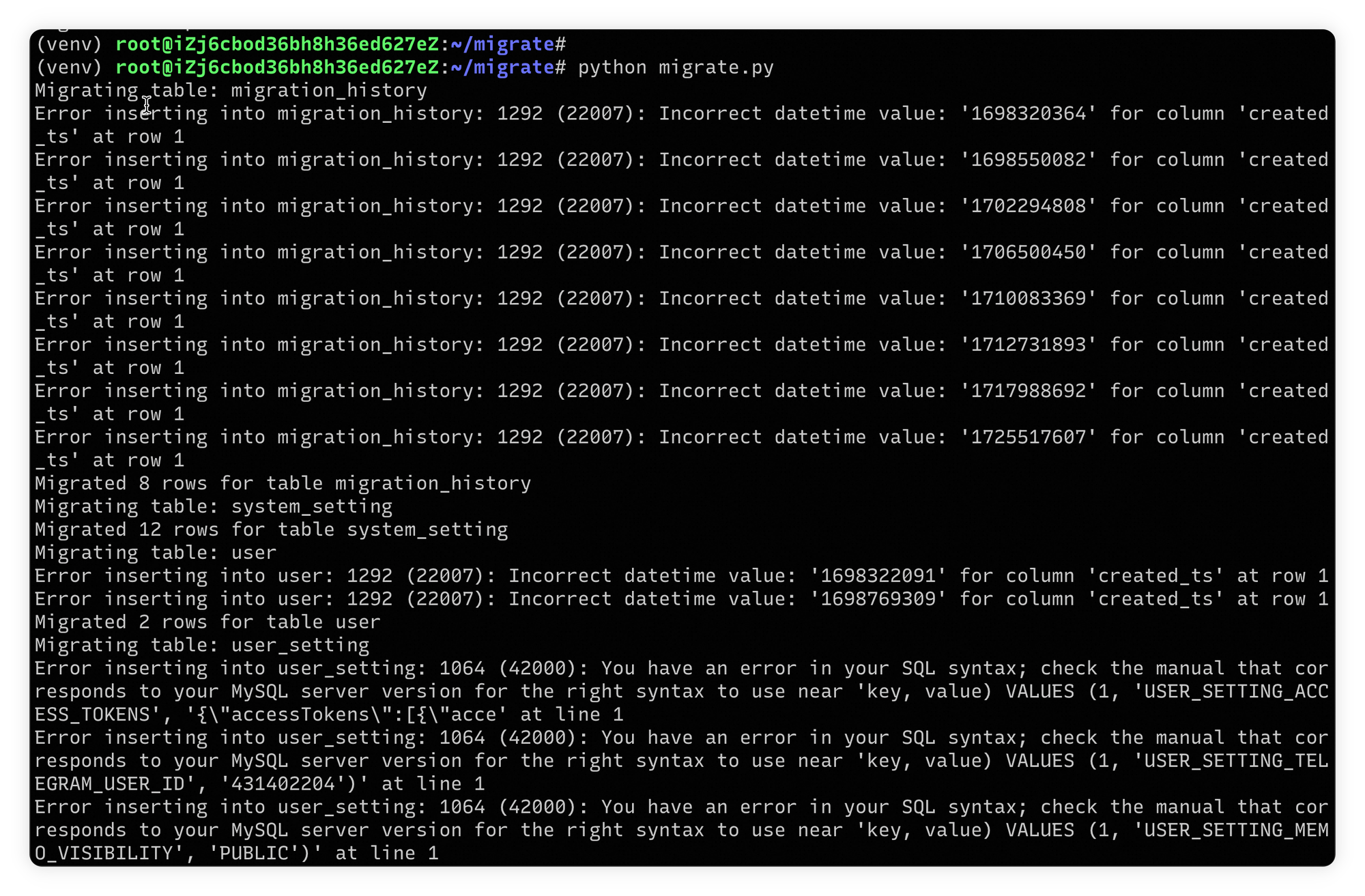
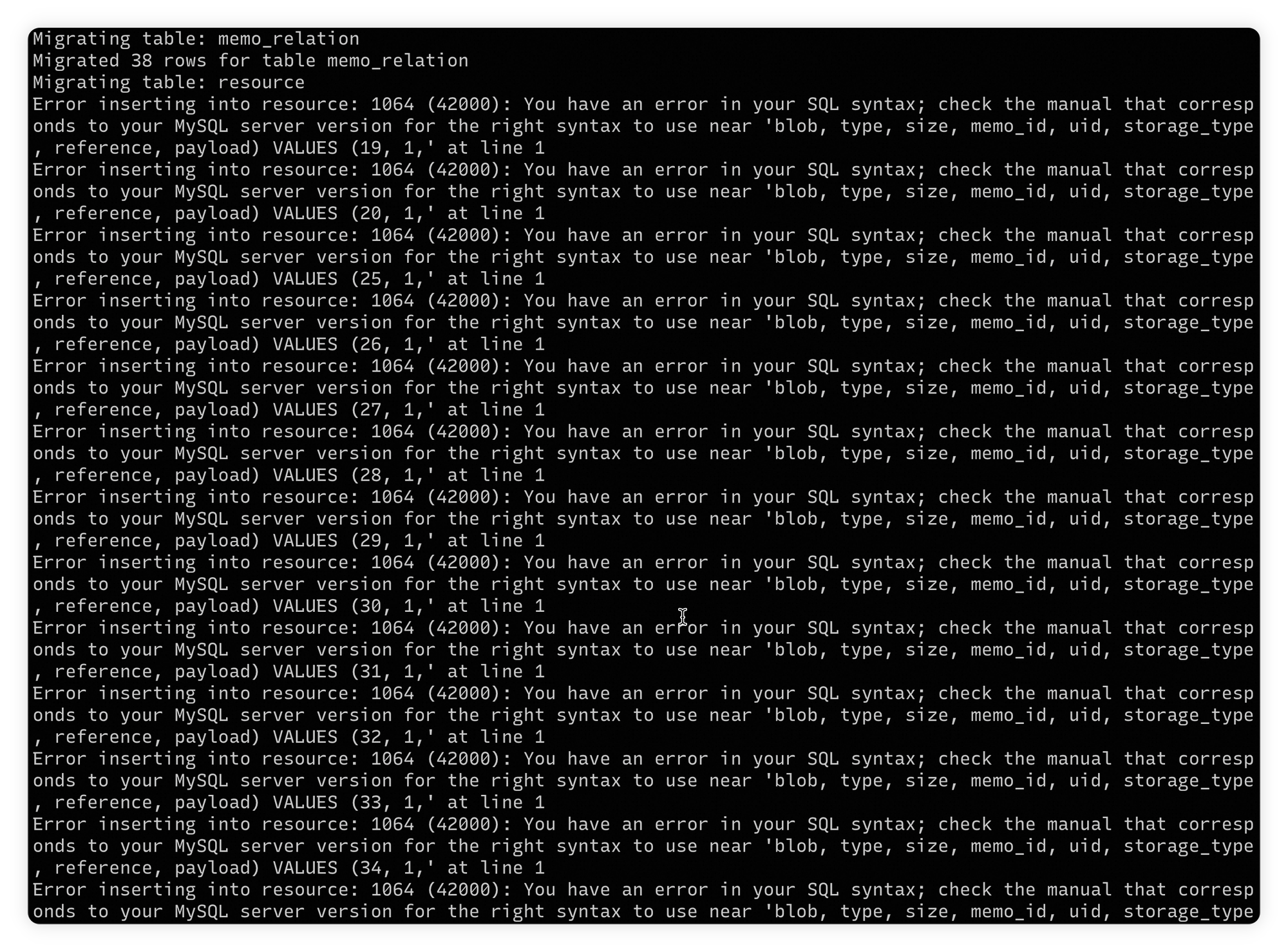
- prompt tuning:
Error inserting into user_setting: 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'key, value) VALUES (1, 'USER_SETTING_ACCESS_TOKENS', '{\"accessTokens\":[{\"acce' at line 1 - prompt result:
I apologize for the oversight. The error is occurring because 'blob' and 'type' are also reserved keywords in MySQL. We need to escape these column names as well. Here's an updated version of the script that handles this issue:
\`\`\`python
import sqlite3
import mysql.connector
import json
from datetime import datetime
# SQLite connection
sqlite_conn = sqlite3.connect('path_to_your_sqlite_database.db')
sqlite_cursor = sqlite_conn.cursor()
# MySQL connection
mysql_conn = mysql.connector.connect(
host="your_mysql_host",
user="your_mysql_user",
password="your_mysql_password",
database="your_mysql_database"
)
mysql_cursor = mysql_conn.cursor()
# List of tables to migrate
tables = [
"migration_history", "system_setting", "user", "user_setting", "memo",
"memo_organizer", "memo_relation", "resource", "activity", "idp",
"inbox", "webhook", "reaction"
]
# List of timestamp columns
timestamp_columns = ['created_ts', 'updated_ts']
# List of reserved keywords that need to be escaped
reserved_keywords = ['key', 'value', 'blob', 'type']
def convert_timestamp(value):
try:
return datetime.fromtimestamp(int(value)).strftime('%Y-%m-%d %H:%M:%S')
except ValueError:
return value
def escape_column_names(columns):
return [f"`{column}`" if column.lower() in reserved_keywords else column for column in columns]
for table in tables:
print(f"Migrating table: {table}")
# Fetch data from SQLite
sqlite_cursor.execute(f"SELECT * FROM {table}")
rows = sqlite_cursor.fetchall()
if not rows:
print(f"No data in table {table}")
continue
# Get column names
columns = [description[0] for description in sqlite_cursor.description]
# Escape column names if necessary
escaped_columns = escape_column_names(columns)
# Prepare MySQL insert query
placeholders = ', '.join(['%s'] * len(columns))
columns_string = ', '.join(escaped_columns)
insert_query = f"INSERT INTO {table} ({columns_string}) VALUES ({placeholders})"
# Insert data into MySQL
for row in rows:
# Convert any JSON fields and timestamps
processed_row = []
for value, column in zip(row, columns):
if column in ['tags', 'payload']:
try:
processed_value = json.dumps(json.loads(value))
except:
processed_value = value
elif column in timestamp_columns:
processed_value = convert_timestamp(value)
else:
processed_value = value
processed_row.append(processed_value)
try:
mysql_cursor.execute(insert_query, processed_row)
except mysql.connector.Error as err:
print(f"Error inserting into {table}: {err}")
print(f"Problematic row: {processed_row}")
continue
mysql_conn.commit()
print(f"Migrated {len(rows)} rows for table {table}")
# Close connections
sqlite_conn.close()
mysql_conn.close()
print("Migration completed")
\`\`\`
The main changes in this updated script are:
1. We've added 'blob' and 'type' to the list of reserved keywords that need to be escaped.
2. The `escape_column_names` function now checks against this expanded list of reserved keywords.
3. I've added a line to print the problematic row when an error occurs, which can help with debugging if you encounter any other issues.
This change should resolve the SQL syntax error you encountered with the `resource` table. The script now properly escapes the 'blob' and 'type' column names, which should allow the insertion into the `resource` table to proceed without errors.
If you encounter any other issues, please let me know, and I'll be happy to help further. Also, remember that if your `blob` column contains large binary data, you might need to
3. 完成 prompt tuning
调优完成之后,就可以向正式的 MySQL 数据库实例进行数据迁移了,主要注意点的:
- RDS 中创建好数据库实例之后,需要用
LATEST.sql进行初始化库表 - prompt tuning 步骤在测试环境迁移完成之后,最好用指定 driver 的方式测试一下 memos 服务是否正常,参考:Database Drivers - Memos
- 还可以让 Claude 帮你增加建库表的过程,省去了自己初始化库表的事情了
附录
import sqlite3
import mysql.connector
import json
from datetime import datetime
# SQLite connection
sqlite_conn = sqlite3.connect('~/.memos/memos_prod.db')
sqlite_cursor = sqlite_conn.cursor()
# MySQL connection
mysql_conn = mysql.connector.connect(
host="xxxxxx.rds.aliyuncs.com",
user="xxxxxxxxxxxxxxxxx",
password="xxxxxxxxxxxxx",
database="xxxxxxxxxxxxx"
)
mysql_cursor = mysql_conn.cursor()
# List of tables to migrate
tables = [
"migration_history", "system_setting", "user", "user_setting", "memo",
"memo_organizer", "memo_relation", "resource", "activity", "idp",
"inbox", "webhook", "reaction"
]
# List of timestamp columns
timestamp_columns = ['created_ts', 'updated_ts']
# List of reserved keywords that need to be escaped
reserved_keywords = ['key', 'value', 'blob', 'type']
def convert_timestamp(value):
try:
return datetime.fromtimestamp(int(value)).strftime('%Y-%m-%d %H:%M:%S')
except ValueError:
return value
def escape_column_names(columns):
return [f"`{column}`" if column.lower() in reserved_keywords else column for column in columns]
for table in tables:
print(f"Migrating table: {table}")
# Fetch data from SQLite
sqlite_cursor.execute(f"SELECT * FROM {table}")
rows = sqlite_cursor.fetchall()
if not rows:
print(f"No data in table {table}")
continue
# Get column names
columns = [description[0] for description in sqlite_cursor.description]
# Escape column names if necessary
escaped_columns = escape_column_names(columns)
# Prepare MySQL insert query
placeholders = ', '.join(['%s'] * len(columns))
columns_string = ', '.join(escaped_columns)
insert_query = f"INSERT INTO {table} ({columns_string}) VALUES ({placeholders})"
# Insert data into MySQL
for row in rows:
# Convert any JSON fields and timestamps
processed_row = []
for value, column in zip(row, columns):
if column in ['tags', 'payload']:
try:
processed_value = json.dumps(json.loads(value))
except:
processed_value = value
elif column in timestamp_columns:
processed_value = convert_timestamp(value)
else:
processed_value = value
processed_row.append(processed_value)
try:
mysql_cursor.execute(insert_query, processed_row)
except mysql.connector.Error as err:
print(f"Error inserting into {table}: {err}")
print(f"Problematic row: {processed_row}")
continue
mysql_conn.commit()
print(f"Migrated {len(rows)} rows for table {table}")
# Close connections
sqlite_conn.close()
mysql_conn.close()
print("Migration completed")
Public discussion