
小本本系列:langchain编程框架(2)

AI Agent 作为2025年的绝对的技术风口,程序员比较关心的是如何开发 AI Agent,Agent 本质上是基于大型语言模型(LLM)的应用程序,所以这个问题本质上就是程序员如何基于大语言模型开发应用。
LangChain 是一个开源框架,用于构建基于大型语言模型(LLM)的应用程序,LangChain 提供各种工具和抽象,以提高模型生成的信息的定制性、准确性和相关性。例如,开发人员可以使用 LangChain 组件来构建新的提示链或自定义现有模板。LangChain 还包括一些组件,可让 LLM 无需重新训练即可访问新的数据集。
架构设计领域有个比较流行的术语——乐高架构,当然也可以叫可插拔架构。说白了就是通过对系统基本组件的合理抽象,找到构造复杂系统的统一规律和可达路径,从而实现在降低系统实现复杂度的同时,提升系统整体的扩展性。LangChain 实际上也遵循了乐高架构的思想。当然,作为最关键的乐高组件之一,LLM 的能力自然是我们优先了解的对象,那我们就从 Qwen 的 API 开始吧!
初步封装--SDK
使用 LangChain community 集成包来进行 Qwen 调用可以大大降低代码的开发成本。
代码示例参考:
数据抽象--IO
对于文本生成模型服务来说,实际的输入和输出本质上都是字符串,因此直接裸调用LLM服务带来的问题是要在输入格式化和输出结果解析上做大量的重复的文本处理工作。LangChain当然考虑到这一点,提供了Prompt和OutputParser抽象,用户可以根据自己的需要选择具体的实现类型使用。
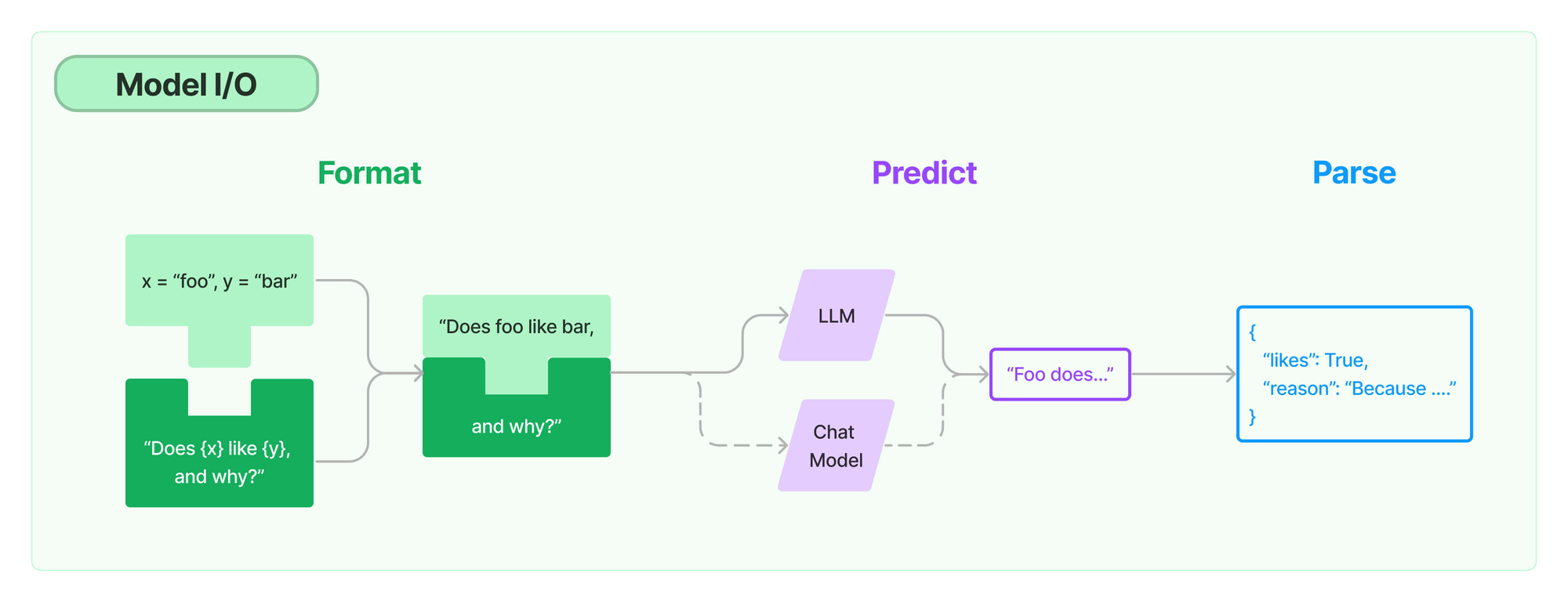
代码示例参考:
链式调用--chain
模型的 IO 组件确实可以减少重复的文本处理工作,但形式上依然不够清晰,这里就引入了 LangChain 中的关键概念:链(Chain)。
LangChain 的表达式语言(LCEL)通过重载__or__运算符的思路,构建了类似 Unix 管道运算符的设计,实现更简洁的 LLM 调用形式。
代码示例参考:
Runnablethrough
当然,为了简化 Chain 的参数调用格式,也可以借助RunnablePassthrough透传上游参数输入。
DAG
Chain 也可以分叉、合并,组合出更复杂的 DAG 计算图结构。
代码示例参考:
通过调用chain.get_graph().print_ascii()可以查看 Chain 的计算图结构。
LangGraph
基于LCEL确实能描述比较复杂的LangChain计算图结构,但依然有DAG天然的设计限制,即不能支持 “循环”。于是LangChain社区推出了一个新的项目——LangGraph,期望基于LangChain构建支持循环和跨多链的计算图结构,以描述更复杂的,甚至具备自动化属性的AI工程应用逻辑,比如智能体应用。其具体使用方式可以参考LangGraph文档。
LangGraph声称其设计理念受Pregel/Beam的启发,构建支持多步迭代的计算能力,支持“流 / 批 / 图”等能力是构建AI Agent的工程基础。
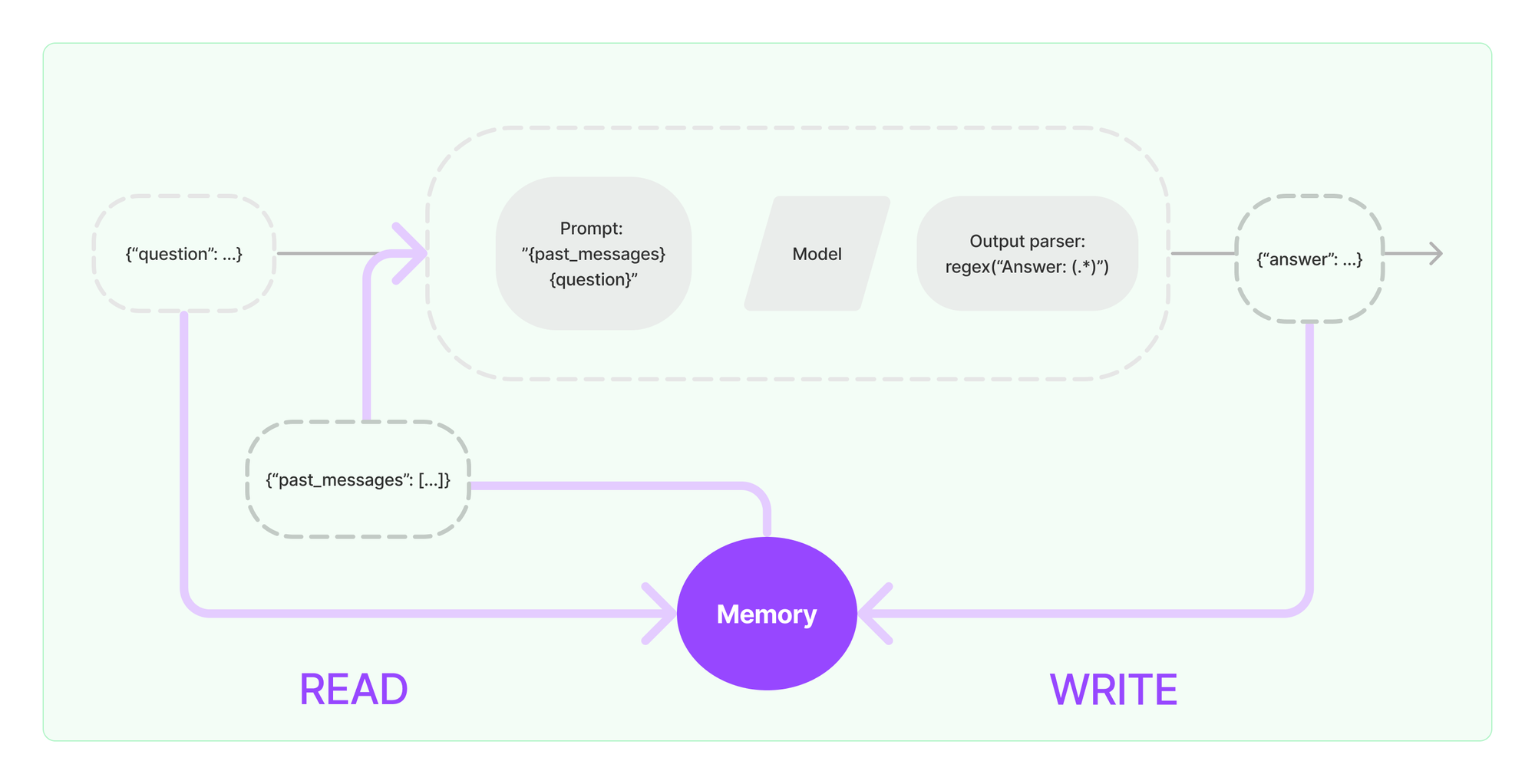
开启记忆--Memory
通过 Chain,LangChain 相当于以 “工作流” 的形式,将 LLM 与 IO 组件进行了有秩序的连接,从而具备构建复杂 AI 工程流程的能力。而我们都知道 LLM 提供的文本生成服务本身不提供记忆功能,需要用户自己管理对话历史。因此引入 Memory 组件,可以很好地扩展 AI 工程的能力边界。
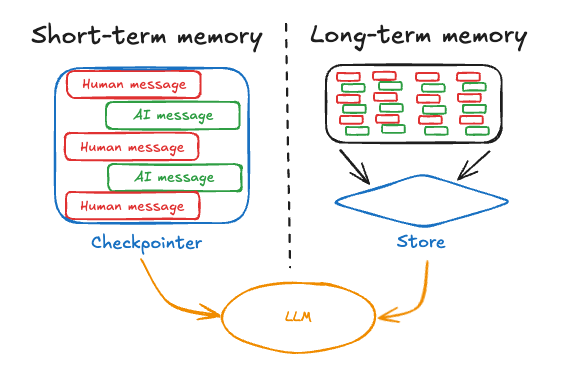
短期记忆 short-term memory
短期记忆让你的应用程序能够在单一的线程或对话中记住之前的交互,对话历史是表示短期记忆的最常见形式。
长对话管理
由于LLM的限制,完整的对话历史(长对话)可能甚至无法适应LLM的上下文窗口,导致不可恢复的错误。即使如果您的LLM在技术上支持完整的上下文长度,大多数LLMs在处理长上下文时仍然表现不佳。它们会被过时或离题的内容“分散注意力”,同时响应时间变慢且成本更高。
管理短期记忆是平衡精准度与召回率与其他性能要求(延迟和成本)的练习。始终重要的是,要批判性地思考如何为您的 LLM 表示信息,并查看您的数据。我们在下面介绍了一些常见的管理消息列表的技术,希望提供足够的背景,让您能够为应用程序选择最佳的权衡方案:
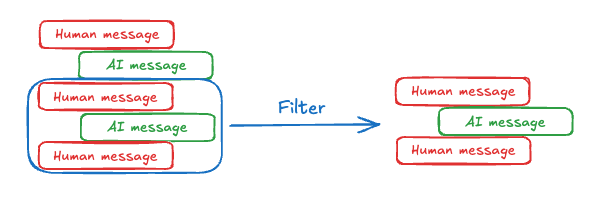
编辑消息列表
在将消息列表传递给语言模型之前进行裁剪和过滤。
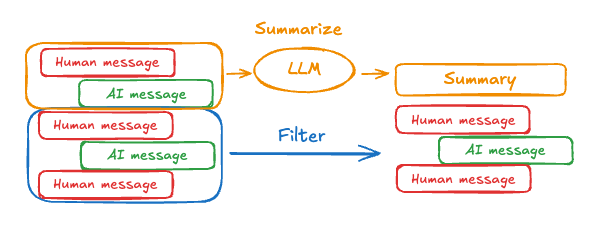
总结过去的对话
修剪或移除消息存在的问题是:我们可能会因消息队列的裁剪而丢失信息,针对这个问题可以通过模型来总结消息历史的方法来解决。
长期记忆 long-term memory
LangGraph 中的长期记忆使系统能够在不同的对话或会话中保留信息。不同于短期记忆,它是线程范围的,长期记忆是保存在自定义的“命名空间”中。
存储记忆
LangGraph 将长期记忆存储为 store (参考文档) 中的 JSON 文档。每个记忆都在自定义 命名空间(类似于文件夹)和唯一的 键(类似于文件名)下组织。命名空间通常包括用户或组织 ID 或其他有助于整理信息的标签。这种结构支持记忆的层次化组织。通过内容过滤器支持跨命名空间搜索。请参见下面的示例。
长期记忆技术选型
长期记忆是一个复杂的挑战,没有一种通用的解决方案。
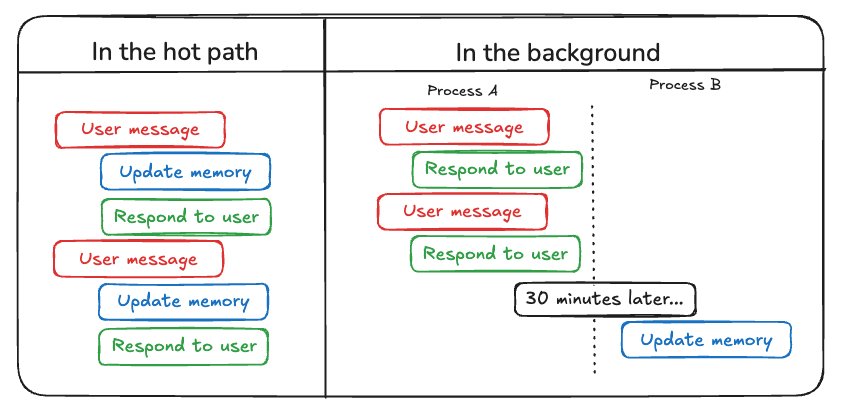
- 记忆类型,不同的记忆类型对应的技术选择不同,具体可以参考Memory Types;

- 何时更新记忆,hot path更新使得记忆立刻生效但会导致延时,background更新灵活没有延时但会有更新不及时的问题,这种技术选型需要更具实际情况和场景考量;
增强工具--Tool
这里不得不提到 OpenAI 的 Chat Completion API 提供的函数调用能力(注意这里不是 Assistant 的函数调用),通过在对话请求内附加 tools 参数描述工具的定义格式(原先叫 functions calling),LLM 会根据提示词推断出需要调用哪些工具,并提供具体的调用参数信息。用户需要根据返回的工具调用信息,自行触发相关工具的回调。
为了简化代码实现,我们用 LangChain 的注解 @tool 定义了一个测试用的 “获取指定城市的当前气温” 的工具函数。然后通过bind_tools方法绑定到 LLM 对象即可。需要注意的是这里需要用JsonOutputToolsParser解析结果输出。
对于Qwen也有自己的tools可以用,推荐使用dashscope sdk,同时百炼平台还支持更多的tools/app调用。
后续
langchain 框架的基本开发就已经完成了,剩下更进阶的内容就是:
消除幻觉--RAG
Retrieval-Augmented Generation,RAG指的是在LLM回答问题之前从外部知识库中检索相关信息,RAG有效地将LLM的参数化知识与非参数化的外部知识库结合起来,使其成为实现大型语言模型的最重要方法之一:
- 早期的神经网络模型,在处理需要依赖外部知识或特定信息的任务时遇到了瓶颈。
- LLM的问题: 幻觉、依赖信息过时、缺乏专业领域知识
- RAG的提出,是为了解决如何将广泛的、分布式的外部信息库与生成模型相结合,从而提高模型在问答、摘要等任务中的性能和准确度
后续我们会继续看看怎么基于langchain框架开发RAG。
走向智能--Agent
AI Agent(人工智能代理)是一种能够感知环境并根据感知到的信息采取行动以实现特定目标的自主系统。它可以在不同的环境中运行,如虚拟环境、物理环境或混合环境。AI Agent 通常具有感知、决策和行动的能力,并且可以通过学习和适应来改进其性能。
Agent当下是兵家必争之地,需要加大投入进行研究和学习,后续先看看langchain框架是如何支持Agent开发的。
P.S. 后续会在 GitHub 开源该文章相关的 ipython noteook,stay tuned
Public discussion