
关于DeepSeek我是怎么研究的(5)

经过了前面一系列关于DeepSeek的研究:
- 关于DeepSeek我是怎么研究的(1):通识RLM推理模型;
- 关于DeepSeek我是怎么研究的(2):了解推理模型背后的模仿人类的背景知识,system 1 & system 2 thinking;
- 关于DeepSeek我是怎么研究的(3):RLM推理机制的详细拆解;
- 关于DeepSeek我是怎么研究的(4):DeepSeek-V3模型的详细分析;
DeepSeek模型的研究系列也接近尾声,不过DeepSeek系列还是会继续写下去,后续更新计划会围绕DeepSeek Day上开源项目展开。
相比V3模型R1就相对简单很多,这篇文章我打算研究一下DeepSeek-R1模型:
R1模型背景
大型语言模型(LLMs)近年来发展迅速逐渐接近人工通用智能(AGI)。后训练阶段是整个训练流程中的一个重要组成部分,它可以提高模型在推理任务上的准确度,使其与社会价值观保持一致,并适应用户偏好,而且与预训练相比,它所需的计算资源相对较少。OpenAI的o1系列模型通过增加推理链(Chain-of-Thought, CoT)的长度,即推理过程,实现了推理时间的扩展,从而在数学、编程和科学推理等任务上取得了显著的进步。然而,有效的测试时间扩展仍然是研究界面临的一个开放性问题。
R1模型概述
DeepSeek-R1-Zero
DeepSeek-R1-Zero是一个基础模型,通过大规模的强化学习(RL)训练而成,未经过监督微调(SFT)。它展示了强大的推理能力,通过RL自然地涌现出了许多强大而有趣的推理行为。例如,在AIME 2024基准测试中,DeepSeek-R1-Zero的pass@1得分从15.6%提高到了71.0%,并且通过多数投票进一步提高到了86.7%,与OpenAI-o1-0912的表现相当。然而,DeepSeek-R1-Zero也面临着一些挑战,比如可读性差和语言混合问题。
DeepSeek-R1
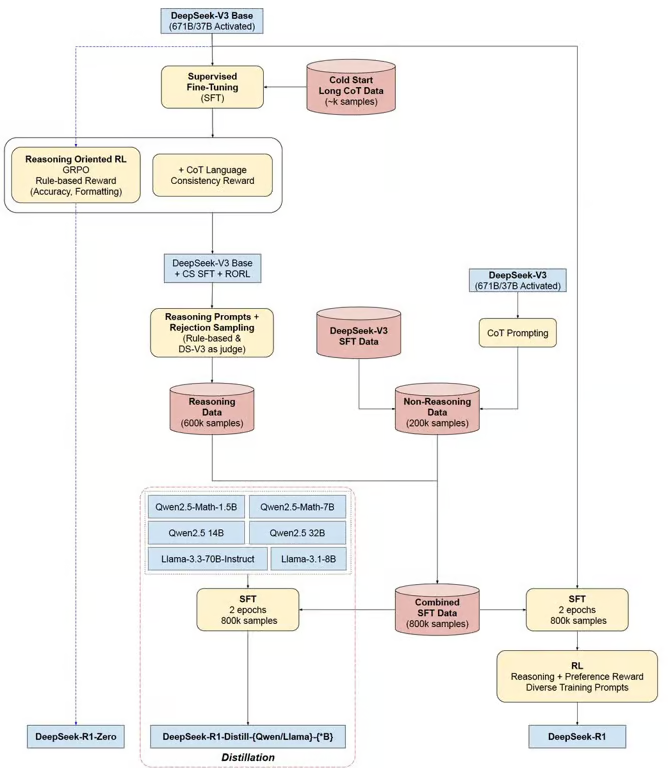
为了解决DeepSeek-R1-Zero的问题并进一步提高推理性能,团队引入了DeepSeek-R1,它结合了多阶段训练和冷启动数据。具体来说,研究团队首先收集了数千个冷启动数据来对DeepSeek-V3-Base模型进行微调。然后,他们执行了类似于DeepSeek-R1-Zero的推理导向RL。在RL过程接近收敛时,研究团队通过对RL检查点进行拒绝采样,结合来自DeepSeek-V3的监督数据(涵盖写作、事实问答、自我认知等领域),然后对DeepSeek-V3-Base模型进行了重新训练。经过两次微调和两次RL阶段的训练后,最终得到的DeepSeek-R1模型在各种推理任务上的表现与OpenAI-o1-1217相当。
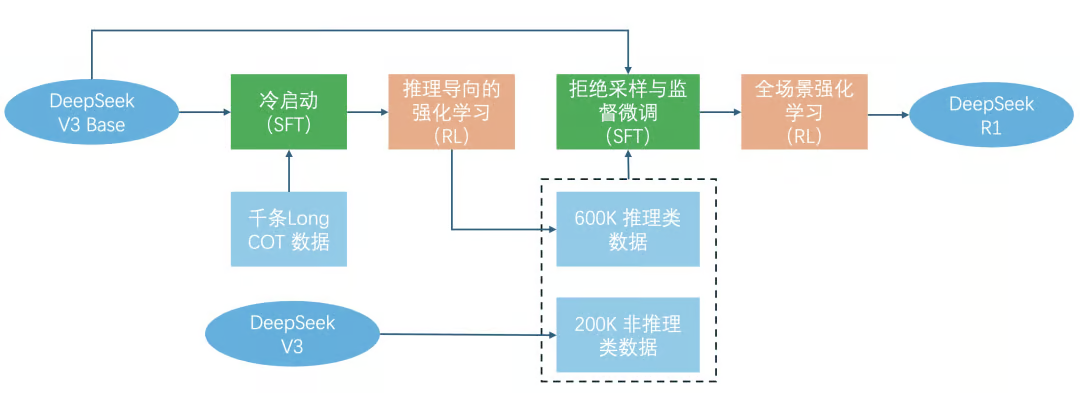
R1并不像R1-Zero那样完全依赖于强化学习过程。训练过程分成四个阶段:
- 冷启动:为了避免RL训练从基础模型开始的早期不稳定冷启动阶段,构建并收集少量长的CoT数据来微调DeepSeek-V3-Base作为RL的起点。
- 推理导向的强化学习:在冷启动数据上微调DeepSeek-V3-Base后,应用与DeepSeek-R1-Zero中相同的RL方法训练。本阶段侧重于增强模型的推理能力,尤其是在编码、数学、科学和逻辑推理等推理密集型任务中,这些任务涉及具有明确解决方案的明确定义的问题。当RL提示涉及多种语言时,CoT经常表现出语言混合现象。为了减轻语言混合问题,在RL训练过程中引入了一种语言一致性奖励。
- 拒绝抽样和监督微调:当2中的RL过程趋于收敛时,利用训练出的临时模型生产用于下一轮训练的SFT数据(600K推理数据)。与1中的冷启动数据区别在于,此阶段既包含用于推理能力提升的600k数据,也包含200k推理无关的数据。使用这800k样本的精选数据集对DeepSeek-V3-Base进行了两个epoch的微调。
- 适用于全场景的强化学习:在3中微调模型的基础上,使用全场景的强化学习数据提升模型回复的有用性和无害性。对于推理数据,遵循 DeepSeek-R1-Zero 的方法,利用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程。对于一般数据,采用基于模型的奖励来捕捉复杂和细微场景中的人类偏好。
R1模型方法
Reinforcement Learning Algorithm
DeepSeek研究团队采用了Group Relative Policy Optimization(GRPO)算法来节省RL的训练成本。GRPO算法不需要与策略模型大小相同的批评者模型,而是从组得分中估计基线。具体来说,对于每个问题,GRPO从旧策略模型中采样一组输出,然后通过最大化以下目标函数来优化策略模型:

Reward Modeling
奖励模型是RL训练信号的来源,决定了RL的优化方向。为了训练DeepSeek-R1-Zero,研究团队采用了一个基于规则的奖励系统,主要包括:
- 准确性奖励:评估响应是否正确。对于数学问题,模型需要以指定格式(例如,在一个框内)提供最终答案,以便可靠地基于规则验证正确性。
- 格式奖励:强制模型将其思考过程放在
<think>和</think>标签之间。
DeepSeek研究团队没有在开发DeepSeek-R1-Zero时应用结果或过程神经奖励模型,因为发现神经奖励模型可能在大规模RL过程中遭受奖励黑客攻击,并且重新训练奖励模型需要额外的训练资源,并且使整个训练流程复杂化。
Training Template
为了训练DeepSeek-R1-Zero,研究团队设计了一个简单的模板,指导基础模型遵循指定的指令。如表1所示,该模板要求DeepSeek-R1-Zero首先生成推理过程,然后生成最终答案。研究团队有意限制约束到这种结构格式,避免对内容进行任何特定内容的偏见,例如,强制反思推理或推广特定问题解决策略,以确保能够准确观察模型在RL过程中的自然演变。

Performance, Self-evolution Process and Aha Moment of DeepSeek-R1-Zero
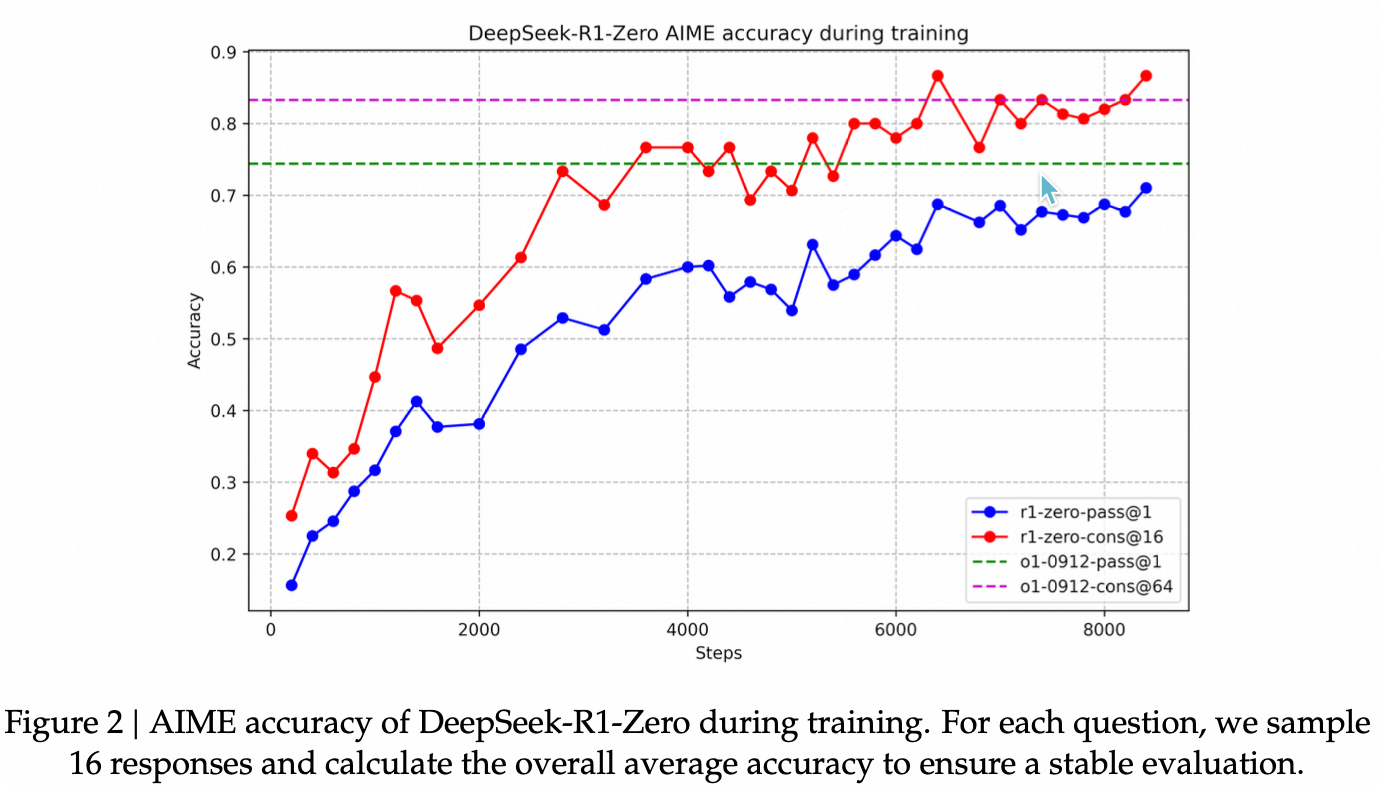
如下图所示,DeepSeek-R1-Zero在AIME 2024基准测试上的准确率随着RL训练过程的进行而稳步提高。具体来说,AIME 2024的平均pass@1得分从初始的15.6%显著提高到了71.0%,达到了与OpenAI-o1-0912相当的性能水平。
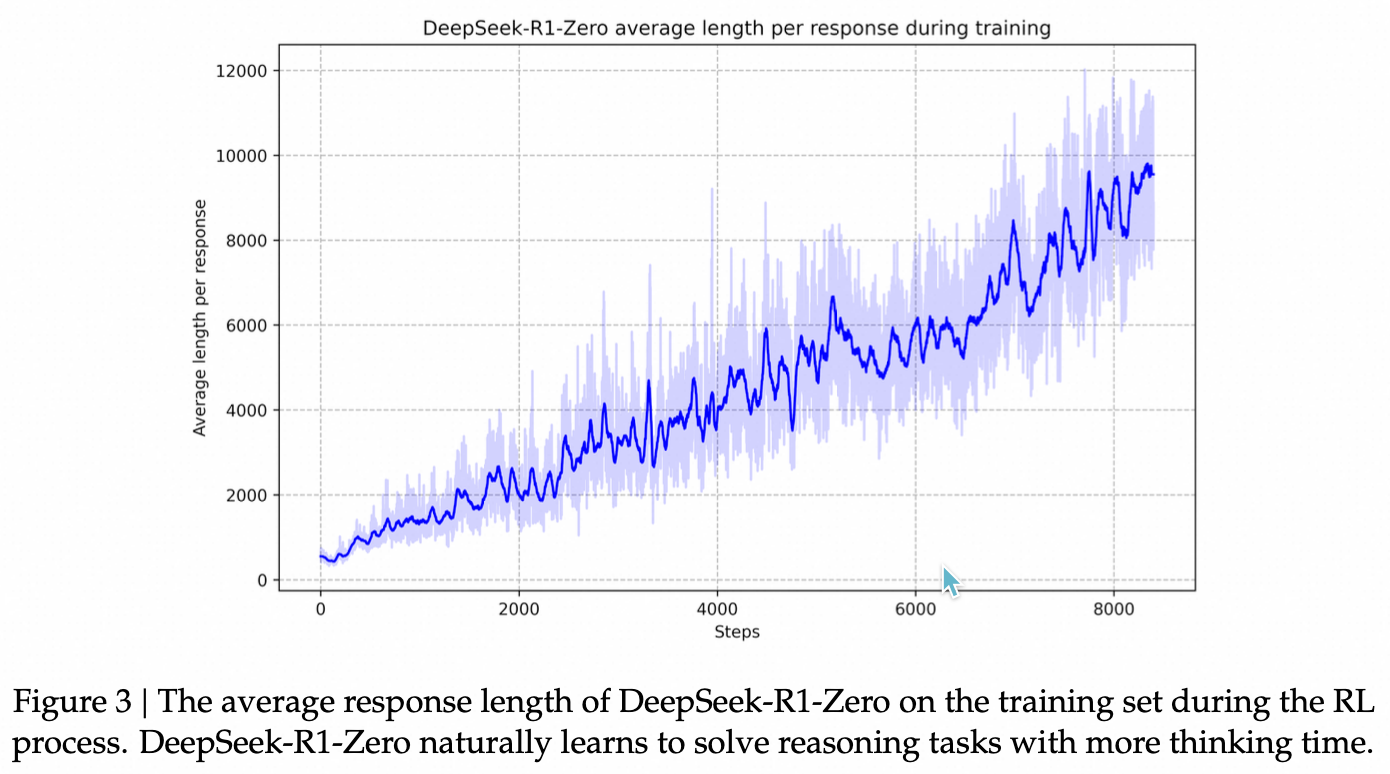
在RL过程的自我进化过程中,DeepSeek-R1-Zero的思考时间表现出一致的改进,如图3所示。这种改进不是外部调整的结果,而是模型内在的发展。DeepSeek-R1-Zero自然地获得了通过扩展测试时间计算解决越来越复杂的推理任务的能力,从生成几百个到几千个推理tokens不等,允许模型更深入地探索和改进其思考过程。
R1模型评估
研究团队在多个基准测试上评估了DeepSeek-R1模型:
- 在英语相关任务上,DeepSeek-R1在AIME 2024上的pass@1得分为79.8%,在MATH-500上的pass@1得分为97.3%,在MMLU上的pass@1得分为90.8%。与DeepSeek-V3相比,DeepSeek-R1在MMLU-Redux上的EM得分为88.9%,在MMLU-Pro上的EM得分为75.9%,在GPQA Diamond上的pass@1得分为71.5%,在DROP上的3-shot F1得分为91.6%,在IF-Eval上的Prompt Strict得分为86.1%,在GPQA Diamond上的pass@1得分为71.5%。
- 在中文相关任务上,DeepSeek-R1在CLUEWSC上的EM得分为85.4%,在C-Eval上的EM得分为76.7%,在C-SimpleQA上的Correct得分为55.4%。
- 在其他任务上,DeepSeek-R1在AlpacaEval 2.0上的LC-winrate得分为87.6%,在ArenaHard上的GPT-4-1106得分为92.3%。
总结
DeepSeek-R1-Zero展示了在没有任何监督微调数据的情况下,通过纯RL过程,LLMs可以发展出强大的推理能力。DeepSeek-R1通过结合冷启动数据和迭代的RL微调,进一步提高了推理性能,并在多个基准测试上达到了与OpenAI-o1-1217相当的性能。此外,通过从DeepSeek-R1蒸馏出较小的密集模型,研究团队还展示了如何将较大模型的推理能力赋予较小的模型。这些蒸馏模型在推理相关的基准测试上表现出了显著的性能提升。
Public discussion