
关于DeepSeek我是怎么研究的(2)

书接上回:关于DeepSeek我是怎么研究的(1),继续我的DeepSeek研究之旅。

这次主要是研究清楚出 DeepSeek 在它的论文中提到的 System 1 Thinking 和 System 2 Thinking,这个概念其实源自于诺贝尔经济学奖得主丹尼尔·卡尼曼(Daniel Kahnemann),他最著名的研究是关于人类决策以及影响我们决策过程的各种缺陷/偏见。在他的《思考,快与慢》这本书中有详细研究和说明了这个概念:
- System 1: 快速、自动、直观且情感化,这是我们的大脑默认运行的系统;
- System 2: 缓慢、费力、逻辑严谨且深思熟虑,我们必须有意激活这个系统,使用这个系统需要很多努力,所以我们不能将其作为默认选项;
- System 1 经常会影响 System 2 的分析,例如我们的分析(System 2)经常会根据符合我们最初概念/直觉(System 1)的精选例子构建叙述,这就是为什么 DeepSeek 会研究用 RL、MoE 等方法来优化模型,这是帮助抵消 System 1 Thinking 对模型决策产生的部分潜在影响;
P.S. :当我发现诺贝尔经济学奖关于人的研究居然应用到了 AI 领域之后,我有点反应过来大模型已经从表层的模仿人类向深层的学习人类过渡了,或许很快就会找到《超验骇客 Transcendence》中的奇异点 Technological Singularity 创造出了能够超越人脑的 AI。
下面我就研究一下 DeepSeek 如何在 RLM 中应用 System 1、2 Thinking 的:
System 1 V.S. System 2
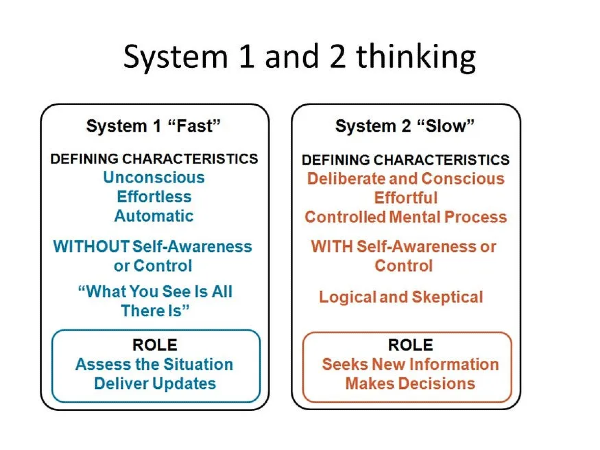
System 1 Thinking(系统1思维)
定义:
System 1 Thinking 是一种快速、直观、基于模式匹配的思维方式。它依赖于预训练的模式和统计规律,能够迅速生成响应。这种思维方式与人类心理学中的“直觉系统”相对应,主要通过识别输入与训练数据中的相似模式,直接生成最可能的输出。
特点:
- 快速响应:能够迅速生成响应,因为它依赖于预训练的模式和统计规律。
- 基于模式匹配:通过识别输入与训练数据中的相似模式,直接生成最可能的输出。
- 启发式方法:使用启发式规则来简化复杂的决策过程,这些规则通常是基于经验或常见的模式。
- 缺乏深度推理:缺乏对复杂问题的深入分析和逐步推理能力,更多地依赖于表面的模式匹配。
- 依赖于训练数据:高度依赖于训练数据中的模式,如果训练数据中没有类似的模式,模型可能无法生成准确的响应。
- 缺乏灵活性:缺乏动态调整推理策略的能力,难以适应新的任务或情境。
System 2 Thinking(系统2思维)
定义:
System 2 Thinking 是一种缓慢、深思熟虑、基于逻辑和结构化分析的思维方式。它依赖于逻辑推理和逐步分析,能够处理复杂的任务和问题。这种思维方式与人类心理学中的“逻辑系统”相对应,主要通过逐步推理和全局评估来生成解决方案。
特点:
- 缓慢且深思熟虑:进行更深入的分析和逐步推理,能够处理复杂的任务。
- 逻辑推理:依赖于逻辑和结构化的分析,能够逐步解决问题。
- 灵活性:能够适应不同的任务和情境,通过动态调整推理策略来解决问题。
- 创新性:能够探索新的解决方案,而不仅仅是依赖于已知的模式。
- 全局评估:通过全局评估推理路径的质量,选择最优的解决方案。
- 依赖于逻辑规则:高度依赖于逻辑规则和推理步骤,能够进行复杂的逻辑分析。
System 1/2对比
| 特性 | System 1 Thinking | System 2 Thinking |
|---|---|---|
| 速度 | 快速生成响应 | 较慢,需要更多时间进行分析 |
| 推理深度 | 缺乏深度推理 | 深入分析和逐步推理 |
| 灵活性 | 缺乏灵活性 | 高度灵活,能够适应不同任务 |
| 依赖 | 依赖于训练数据中的模式 | 依赖于逻辑规则和推理步骤 |
| 结果 | 生成连贯但可能缺乏深度的文本 | 生成经过深思熟虑的解决方案 |
| 应用场景 | 适合生成连贯文本和快速响应 | 适合处理复杂问题和需要深入分析的任务 |
System 1/2 在 RLM 的应用
System 1与System 2的交互
人类思考的过程中 System 1 经常起主导作用,它高效运行防止我们的大脑因过度分析而陷入困境。这是通过使用认知偏差来实现的。尽管偏差通常被视为贬义词,但实际上它们是一种中性的现象。从信息理论的角度来看,偏差只是决策模型(无论是我们的大脑还是 AI)用来优先处理和使用信息的一种捷径。 这种偏差可以是积极的(因为某物气味奇怪而不吃它),中性的(我喜欢巧克力牛奶),或者是消极的(种族偏见)。
人类和 AI 偏差之间的主要区别在于其来源:人类的偏差源于结构,而 AI 的偏差则揭示了我们数据的深层次问题。
在 AI 领域中,System 1 是一个简单的检查器,而 System 2 是一个功能强大的深度学习模型。然而,System 1 的作用并不仅限于此。在大多数情况下,System 1 还充当我们的特征提取器/数据管道,直接提供输入给 System 2。以下是两种主要方式:
- Confirmation Bias(确认偏误):System 1 的 Confirmation Bias 通过寻找支持我们现有信念的信息并忽略与之矛盾的信息来强化这些信念,这会形成对现实的扭曲认知。
- Framing Effects(框架效应): 信息的呈现方式(即“框架”)可以影响我们的决策,即使基本事实保持不变。System 1 更容易受到 Framing Effects 的影响,导致选择受呈现方式而非逻辑的影响。
System 1、2 的均值回归
Reversion to the Mean(均值回归)描述了极端结果或事件之后往往会跟随较不极端的结果,直到情况收敛回到平均值的统计倾向。这听起来非常显而易见,但理解其含义对任何决策者(尤其是那些处理数据的人)至关重要。几个因素促成了 System 1/2 的均值回归:
- Random Variation(随机变异):任何结果都受偶然因素影响。一个 exceptional result 可能只是由于一连串的好运/外部因素,这种情况不太可能再次发生。
- Measurement Error(测量误差): 测试和测量并非完美。异常高或低的分数可能部分受到测量误差的影响,导致后来的结果更为平均。
- Underlying Stability(内在稳定性):大多数系统都有一个自然的平均值或平衡状态,它们倾向于向这个状态靠拢。偏离这个平均值的情况通常会随着时间自行纠正。
基于上面的 System 1、2 均值回归的理解,RLM 的设计、训练等过程中需要注意避免错误推理:
- Misinterpreting Performance(误读表现):我们需要小心,不要高估一次极端表现(无论是正面的还是负面的)的影响。均值回归表明,这可能部分是偶然现象,而不是永久性变化的真实反映。
- Evaluating Interventions(评估干预措施): 如果我们做出改变(比如启动一个新的员工培训计划),然后观察到极大的改进,我们可能会倾向于将这种变化完全归因于干预措施。然而,均值回归也可能在起作用,我们需要考虑到这一点,以便正确评估结果。
- Predicting the Future(预测未来):均值回归表明,从最近的极端结果过度外推通常是误导性的。未来的结果可能会不那么极端。这就是为什么改进数据采样和理解底层领域至关重要,因为这两者都有助于我们评估某一组先前的数据是否是预测未来的良好模型。
P.S.:我慢慢理解为什么 DeepSeek 做数据蒸馏之后的训练效果还是那么好了!
损失规避
丹尼尔·卡尼曼关于损失厌恶的研究发现,避免损失的动机是追求同等规模胜利动机的 2.5 倍。
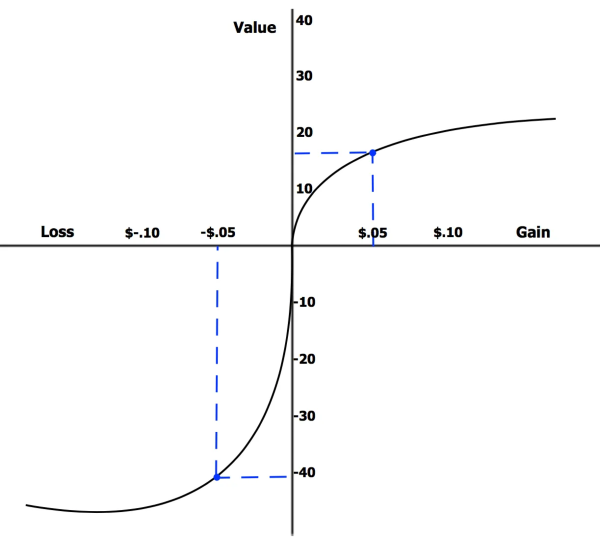
以下是跟 AI 相关的损失规避的规律:
- Anchoring Bias(锚定偏差):我们倾向于过度关注所提供的第一个信息(“锚点”),可以使用完全不相关的事物作为锚点,锚定偏见可能会加剧自动化偏见的影响(我们倾向于对自动化决策系统的结果接受得更加不加批判)。
- Framing Effects(框架效应):信息的呈现方式(“框架”)极大地影响我们如何感知它以及我们所做的决定,故意为其基准/技术命名以引导做出有利的决策,AI 的基准测试 TruthfulQA 非常好的说明了这一点。
- Availability Heuristic(可用性启发式):我们通过例子浮现脑海的容易程度来评估事件的可能性或频率,而不是根据其真实的基本概率。这经常导致对真实概率的误判,社交媒体的性质倾向于推送最极端的内容/创作者,因此那些花很多时间上网的人可能会把这些异常情况误认为是“正常”的。
- Representativeness Heuristic(代表性启发法):我们根据事物或人与典型例子的相似程度来做出判断,有时会忽略统计概率。LLMs 在模仿人类智能和语言理解的行为方面表现出色,但并未显示出智能的底层驱动因素。
P.S.:用 RL 在 RLM 的 post 阶段增强推理思考的处理看上去是有据可循的。
在 RLM 中的应用
System 1 Thinking 在 RLM 中的应用:
- 生成推理步骤:在 RLM 中,System 1 Thinking 通过策略模型(Policy Model)生成新的推理步骤。策略模型基于大型语言模型(LLM),能够快速生成连贯的文本,推动推理过程的进展。
- 模式匹配:策略模型依赖于模式匹配和统计规律,能够迅速生成下一个最可能的推理步骤,适用于快速生成推理路径的场景。
System 2 Thinking 在 RLM 中的应用:
- 评估推理路径:在 RLM 中,System 2 Thinking 通过价值模型(Value Model)评估推理路径的质量。价值模型能够进行全局评估,选择最有希望的推理路径,优化推理过程。
- 推理策略:System 2 Thinking 通过推理策略(如蒙特卡洛树搜索 MCTS)来平衡探索和利用,优化推理路径的选择和扩展。MCTS 通过模拟多个推理路径并选择最优路径,体现了 System 2 Thinking 的全局评估和逐步推理能力。
结合 System 1 和 System 2:
- RLM 的推理过程:RLM 通过结合 System 1 和 System 2 的思维方式,实现了对复杂问题的高效解决。策略模型生成新的推理步骤(System 1),价值模型评估推理路径的质量(System 2),两者共同推动推理过程的进展。
- 训练机制:RLM 的训练机制包括监督学习(SFT)和强化学习(RL),通过优化策略模型和价值模型,提高模型的推理能力和泛化能力。监督学习确保模型能够生成高质量的推理步骤,强化学习通过与环境的交互,进一步优化推理策略。
总结
System 1 Thinking 和 System 2 Thinking 在 RLM 中各有其独特的应用和优势。System 1 Thinking 通过快速生成推理步骤,推动推理过程的进展;System 2 Thinking 通过全局评估和逐步推理,优化推理路径的选择和扩展。通过结合这两种思维方式,RLM 能够高效地解决复杂问题,生成高质量的推理路径,并在各种任务中表现出色。
Public discussion