
关于DeepSeek我是怎么研究的(1)

DeepSeek 从春节前开始进入大众的视线,一个月之前我连幻方量化这个名字都没有听说过,但是它如今的火爆程度甚至上升到国与国之间的竞争,这其中除了技术探讨更多的是带着立场的营销文章,乱花渐入迷人眼,国内关于 DeepSeek 的讨论已经脱离了理性只有吹捧和政治正确。
我觉得这是一个很好的锻炼机会,面对纷繁复杂的数据信息、舆论立场,我如何通过理性的思考建立自己对 DeepSeek 的认知,通过此次实践进一步总结形成自己不被外部影响的认知思路和方法,这才是更有意义的。研究一个东西我自己有一个习惯:找到最源头的信息,回到怎么建立对 DeepSeek 的认知这个问题上,我打算抛开所有大 V 的文章、解读、总结演绎过的内容,回到 DeepSeek 最原始的信息 —— DeepSeek开源的论文和报告。
关于 DeepSeek 的研究我打算分成几个部分:
- RLM推理言语模型是什么
- 对比 System 1 thinking 和 System 2 thinking
- 推理框架Reasoning Schema是什么
- DeepSeek V3 的技术架构与研究成果是什么
- DeepSeek R1 的用了哪些技术和研究方法
- DeepSeek 技术原创性分析以及给我们的启发
所以这会是一个系列文章,Stay Tuned。
RLM
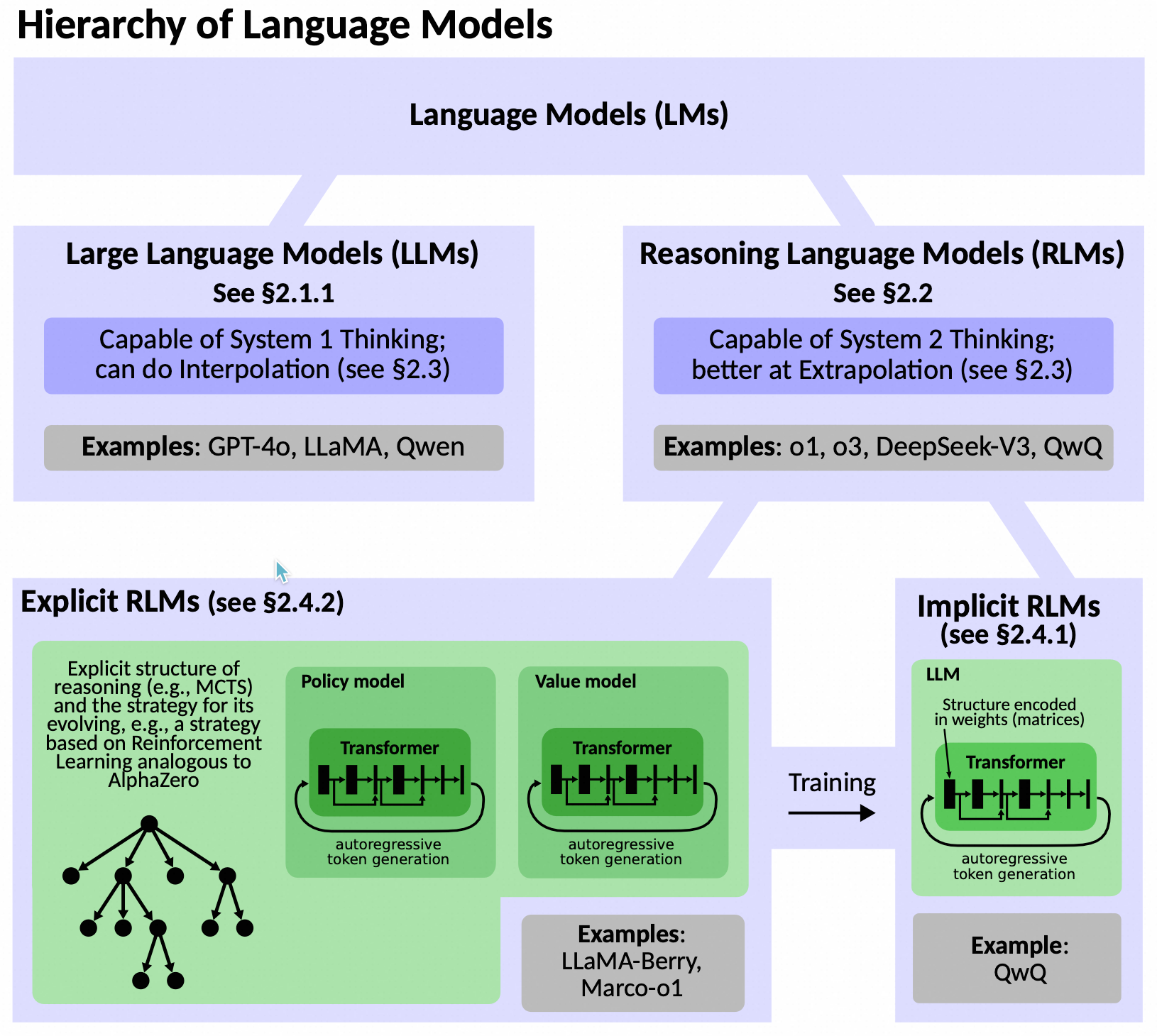
Reasoning Language Model (RLM) 可以定义为一种结合了大型语言模型(LLMs)的生成能力和高级推理机制的人工智能模型。RLMs 通过引入结构化的推理过程,能够进行复杂的逻辑分析和逐步推理,从而解决需要深入思考的问题。
定义
Reasoning Language Model (RLM) 是一种高级人工智能模型,它通过结合大型语言模型(LLMs)的生成能力和强化学习(RL)、蒙特卡洛树搜索(MCTS)等推理机制,实现了对复杂问题的系统化、结构化推理。RLMs 能够进行多步骤的逻辑分析,生成高质量的推理路径,并通过自学习不断优化其推理策略。
核心组件
- 推理结构(Reasoning Structure):
- 定义:推理结构是RLM推理过程的组织形式,通常以树状、链状或图状结构表示。每个节点代表一个推理步骤,节点之间的连接表示推理路径。
- 作用:推理结构帮助模型系统地探索可能的解决方案,逐步构建完整的推理路径。
- 策略模型(Policy Model):
- 定义:策略模型是一个基于LLM的神经网络,用于生成新的推理步骤。它根据当前的推理状态,预测下一个最有可能的推理步骤。
- 作用:策略模型通过生成新的推理步骤,推动推理过程的进展。它是System 1 Thinking的体现,依赖于模式匹配和统计规律。
- 价值模型(Value Model):
- 定义:价值模型是一个基于LLM的神经网络,用于评估推理路径的质量。它预测从当前节点开始的推理路径的预期累积奖励。
- 作用:价值模型帮助模型选择最有希望的推理路径,优化推理过程。它是System 2 Thinking的体现,依赖于对推理路径的全局评估。
- 推理策略(Reasoning Strategy):
- 定义:推理策略是RLM中用于指导推理结构如何演变的算法。常见的推理策略包括蒙特卡洛树搜索(MCTS)、束搜索(Beam Search)和集成方法(Ensemble Methods)。
- 作用:推理策略通过平衡探索和利用,优化推理路径的选择和扩展。
- 训练机制(Training Mechanism):
- 定义:RLM的训练机制包括监督学习(Supervised Fine-Tuning, SFT)和强化学习(Reinforcement Learning, RL)。SFT用于训练策略模型和价值模型,使其能够生成和评估高质量的推理步骤。RL通过与环境的交互,进一步优化模型的推理策略。
- 作用:训练机制通过优化策略模型和价值模型,提高模型的推理能力和泛化能力。
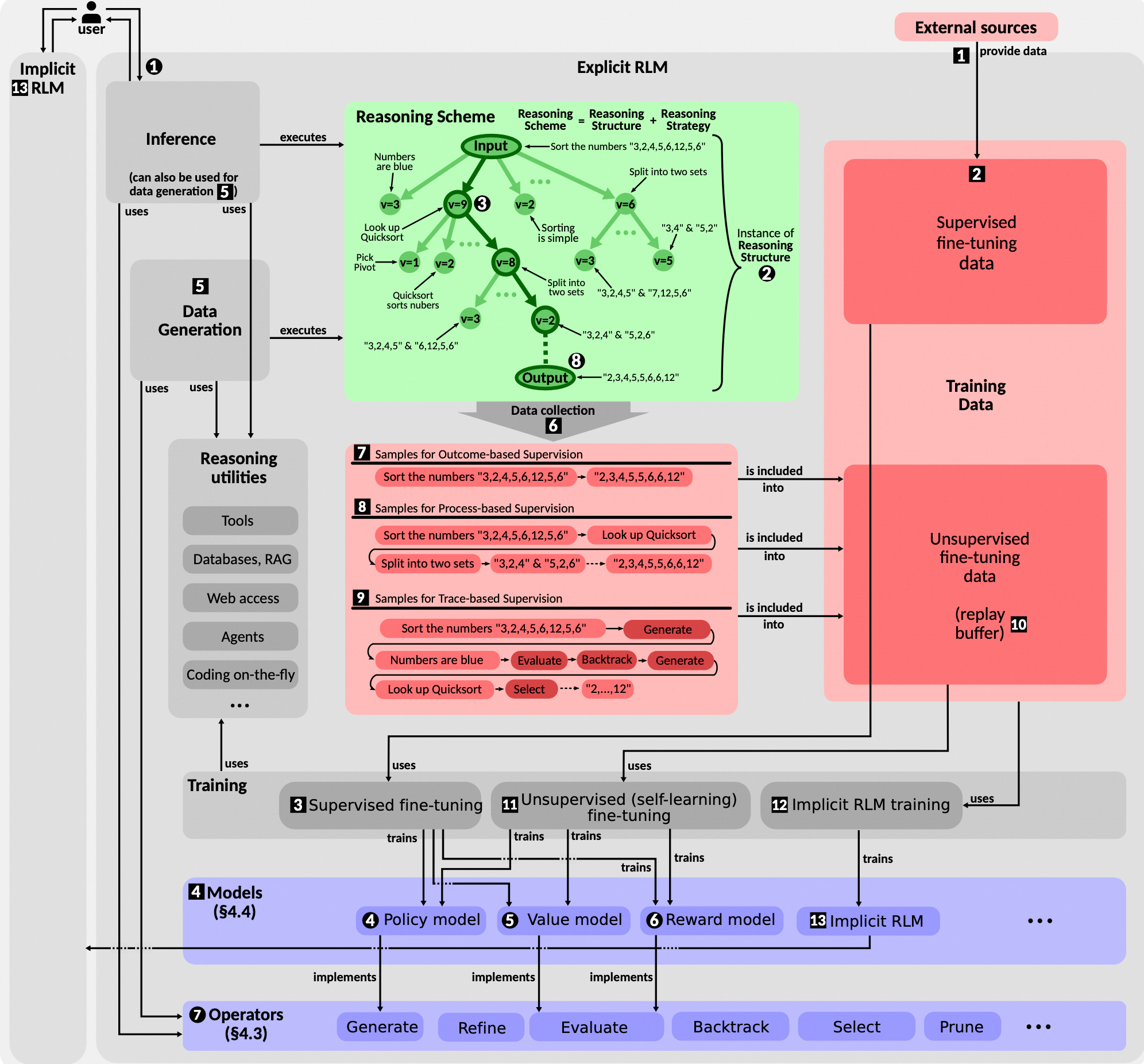
工作原理
- 推理过程(Inference Process):
- 用户输入:用户提供问题或任务描述,作为推理的起点。
- 推理结构构建:模型构建一个推理结构,通常以树状结构表示,每个节点代表一个推理步骤。
- 策略模型生成:策略模型生成新的推理步骤,扩展推理结构。
- 价值模型评估:价值模型评估推理路径的质量,帮助模型选择最有希望的路径。
- 终止步骤:当达到终止步骤时,推理过程结束,形成最终答案。
- 训练过程(Training Process):
- 监督微调(SFT):使用标注数据训练策略模型和价值模型,使其能够生成和评估高质量的推理步骤。
- 强化学习(RL):通过与环境的交互,优化模型的推理策略,使其能够更好地选择和评估推理路径。
- 自学习(Self-Learning):模型通过模拟推理过程生成新的数据,这些数据用于重新训练模型,进一步优化其推理能力。
- 数据生成(Data Generation):
- 独立于用户请求:数据生成部分独立于用户请求,通过模拟推理过程生成新的训练数据。
- 多样性:生成多样化的推理路径,确保模型能够处理各种复杂情境。
特点
- 结合System 1和System 2:RLMs结合了LLMs的快速生成能力(System 1 Thinking)和高级推理机制(System 2 Thinking),实现了对复杂问题的高效解决。
- 结构化推理:通过构建推理结构和采用推理策略,RLMs能够进行多步骤的逻辑分析,生成高质量的推理路径。
- 自学习能力:通过自学习和强化学习,RLMs能够不断优化其推理策略,提高推理能力和泛化能力。
- 模块化设计:RLMs的架构支持模块化设计,便于实验和优化,能够适应不同的任务需求。
总结
Reasoning Language Model (RLM) 是一种结合了大型语言模型的生成能力和高级推理机制的高级人工智能模型。通过构建推理结构、采用推理策略和优化训练机制,RLMs能够进行复杂的逻辑分析和逐步推理,从而解决需要深入思考的问题。这种模型不仅提高了推理能力,还增强了泛化能力和适应性,为解决复杂问题提供了新的途径。
Public discussion