
用好 AI:TRIRO 框架

LLM 的一些基础知识
LLM 参数
- 温度 - temperature 越低,结果就越确定,因为总是选择最高可能的下一个标记。温度升高可能会导致更多的随机性,从而鼓励更多样或创造性的产出。实际上是在增加其他可能标记的权重。在应用方面可能希望对基于事实的 QA 等任务使用较低的温度值,以鼓励更真实和简洁的响应。对于诗歌生成或其他创造性任务,增加温度值可能会有好处。
- Top P - 一种带有温度的采样技术,称为核采样,可以在其中控制模型的确定性。如果是寻找准确且真实的答案,请将其保持在较低水平。如果是寻找更多样化的响应可以增加到更高的值。如果使用 Top P 则意味着只有包含 Top P 概率质量的标记才被考虑用于响应,因此较低的 Top P 值会选择最有信心的响应。这意味着较高的 Top P 值将使模型能够查看更多可能的单词,包括不太可能的单词,从而产生更多样化的输出。与 temperature 和 Top P 类似,一般建议是更改频率或存在惩罚,但不能同时更改两者。
- 最大长度 - max length 控制模型生成的令牌数量。指定最大长度有助于防止过长或不相关的响应并控制成本。
- 停止序列 - stop sequence 是一个停止模型生成标记的字符串。指定停止序列是控制模型响应的长度和结构的另一种方法。例如可以通过添加“11”作为停止序列来告诉模型生成不超过 10 个项目的列表。
- 频率惩罚 - frequency penalty 对下一个标记应用惩罚,该惩罚与该标记已在响应和提示中出现的次数成比例。频率惩罚越高,某个词再次出现的可能性就越小。此设置通过给予看起来更多的标记更高的惩罚来减少模型响应中单词的重复。
- 存在惩罚 - presence penalty 还对重复标记应用惩罚,但与频率惩罚不同,惩罚对于所有重复标记都是相同的。出现两次的令牌和出现 10 次的令牌受到相同的惩罚。此设置可防止模型在响应中过于频繁地重复短语。如果希望模型生成多样化或创造性的文本需要使用更高的存在惩罚,如果需要模型保持专注可以使用较低的存在惩罚。
Prompts
What
prompts 有时被称为上下文,是在模型开始生成输出之前提供给它的文本,它指导模型根据训练的知识输出与目标相关的内容。我们使用 prompts 让语言模型做我们希望它做的事情——就像软件工程是编写源代码让计算机做我们希望它们做的事情一样。有一个比较形象的比喻:prompts 是 python 代码,大模型是 python 解释器。
在编写好的 prompts 时,必须考虑到所使用的模型的特质,使用策略将随着任务的复杂性而变化。必须想出机制来约束模型以获得可靠的结果,纳入模型无法训练的动态数据,考虑模型训练数据的限制,围绕上下文限制进行设计,以及许多其他维度。
Hidden Prompts
在用户与模型动态交互(例如与模型聊天)的应用程序中,通常会有用户不想看到的提示部分。这些隐藏部分可能出现在任何地方,尽管在对话开始时几乎总是有隐藏提示。 通常,这包括设定基调、模型约束和目标的初始文本块,以及特定于特定会话的其他动态信息 - 用户名、位置、一天中的时间等...... 该模型是静态的并冻结在某个时间点,因此如果希望它了解当前信息,例如时间或天气,则必须提供它。 如果使用 OpenAI Chat API,它们会通过将隐藏的提示内容放置在 system 角色中来描述隐藏的提示内容。
Prompts Security
安全使用 LLM 模型的问题一定要谨记如下安全假设:
- 始终假设一个坚定的用户能够绕过 LLM 对于 prompt 的约束
- 始终假设暴露在 LLM 中的任何数据最终都会被用户看到
Token
Token 源自于 LLMs 在做数据预处理时的一种数据标记方法,一般被称为 tokenize,被预处理后的数据在数学意义上被称为 tensor 张量(TensorFlow 都很熟悉,这下知道名字的由来了吧!)。
关于张量 tensor,TensorFlow 是这么定义的:
A tensor is a generalization of vectors and matrices to potentially higher dimensions.(张量是多维数组,目的是把向量、矩阵推向更高的维度。)
普通人理解版本:
- 点——标量(scalar)
- 线——向量(vector)
- 面——矩阵(matrix)
- 体——张量(tensor)
在数据集上训练模型之前,需要将其预处理为预期的模型输入格式。无论数据是文本、图像还是音频,都需要将它们转换并组装成批量张量。Transformers 提供了一组预处理类来帮助为模型准备数据:
- 文本,使用 Tokenizer 将文本转换为标记序列,创建标记的数字表示,并将它们组装成张量。
- 语音和音频,使用特征提取器从音频波形中提取顺序特征并将其转换为张量。
- 图像输入使用 ImageProcessor 将图像转换为张量。
- 多模态输入,使用处理器来组合分词器和特征提取器或图像处理器。
下面是 python 代码做文本标记:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
print(encoded_input)
# output:
{'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
GPT3.5&GPT4 语言模型标记示例:
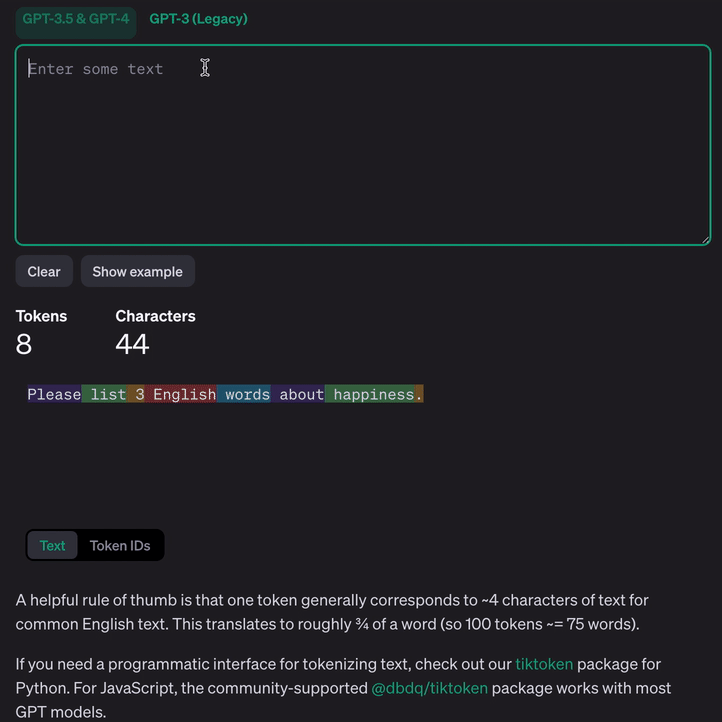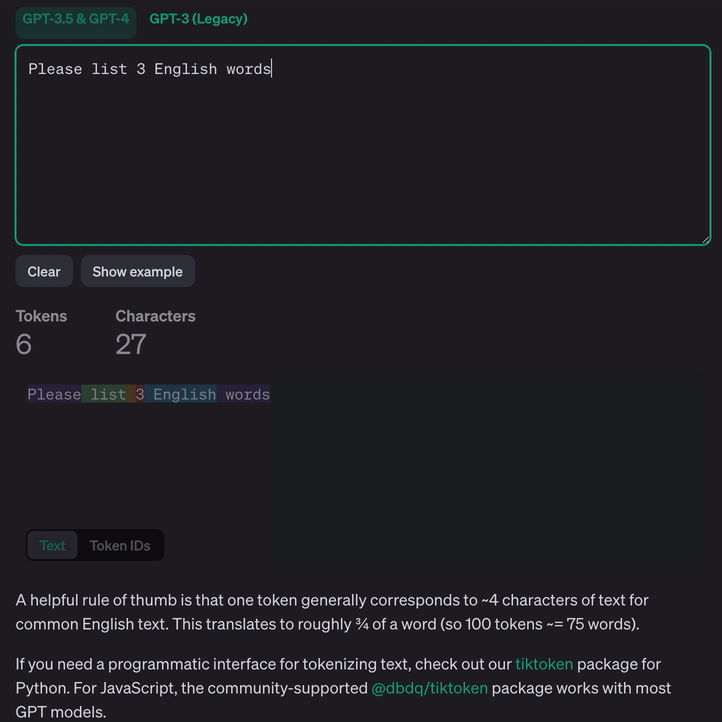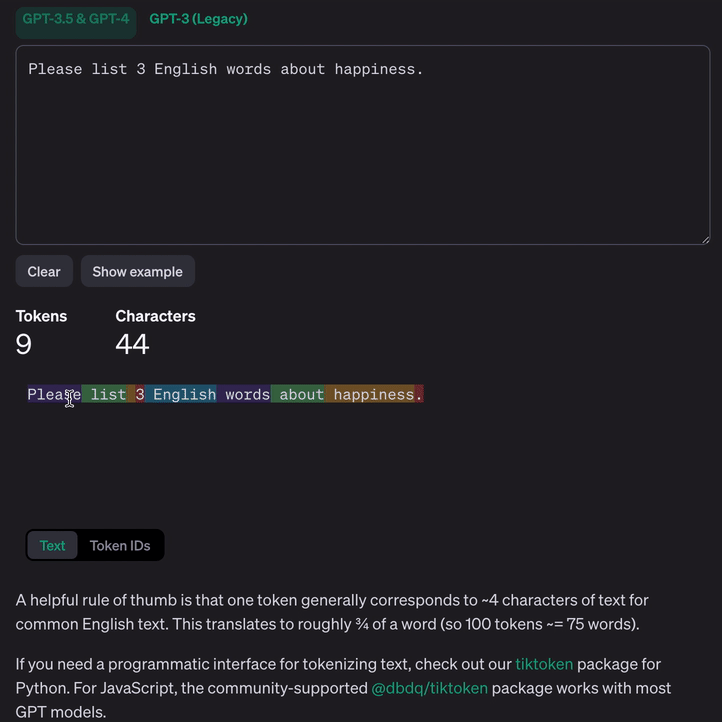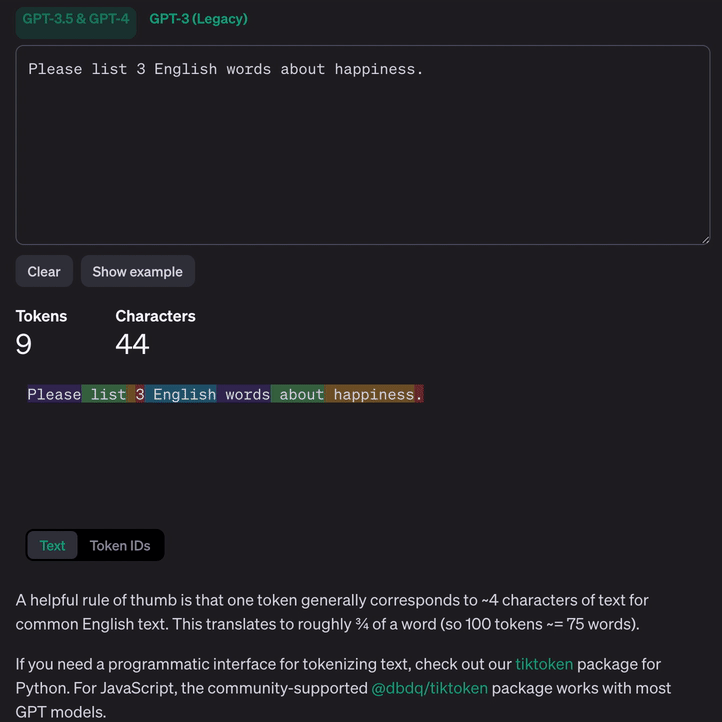
Why Token
标记化语言将其转换为数字——计算机可以实际处理的格式。使用 Token 而不是单词使 LLM 能够处理更大量的数据和更复杂的语言。通过将单词分解为更小的部分(Token),LLM 可以通过理解其构建块来更好地处理新的或不常见的单词。它还有助于模型掌握语言的细微差别,例如不同的词形和上下文含义。从本质上讲,使用 Token 就像为模型提供了更详细的语言地图,使其能够更有效地导航和理解人类交流的复杂性,即使数据有限或使用不同的语言也是如此。
Token 也是一种有用的衡量形式。 LLM 可以处理和生成的文本大小以标记来衡量。此外,LLMs 的运营费用与其处理的令牌数量成正比 —— 令牌越少,成本越低,反之亦然。
Token Limits
一般来说,语言模型是无状态的,不会记住之前向它们发出的请求的任何信息,因此需要始终包含它可能需要知道的特定于当前会话的所有内容。
语言模型架构 Transformer 有一个不足之处:它只具有固定的输入和输出大小 —— 在某个点上提示符不能再变大。Prompt 的总大小(有时称为“上下文窗口”)取决于型号,对于 GPT-3,它是 4,096 个代币;对于 GPT-4,它是 8,192 个令牌或 32,768 个令牌,具体取决于哪种变体变体。
如果上下文对于模型来说太大,最常见的策略是以滑动窗口方式截断上下文。如果将提示视为 hidden initialization prompt + messages[] ,通常隐藏的提示将保持不变,并且 messages[] 数组将获取最后 N 条消息。还可能会看到更聪明的提示截断策略,例如首先仅丢弃用户消息以便机器人之前的答案尽可能长时间地保留在上下文中,或者要求 LLM 总结对话然后用包含该摘要的单个消息替换所有消息。重要的是,在截断上下文时必须足够积极地截断,以便为响应留出空间。 OpenAI 的代币限制包括输入的长度和输出的长度。如果向 GPT-3 的输入是 4,090 个令牌,它只能生成 6 个令牌作为响应。
Prompt Engineering 和 TRIRO
特别说明: TRIRO 是侯智薰 (雷蒙)提出来的一套方法论,如果感兴趣有详细的课程可供参考。我这里只是根据自己的理解做的简单的总结和针对自己需求的定制化修改。
AI 相关的一些原则
基本观念
别把 AI(ChatGPT) 当作搜寻引擎,而是要当作一个懂很多的「学霸助理」。它的本质不是用来搜寻正确答案,AI(ChatGPT) 很会找资料、重组内容结构没错,但对于内容的合理性却没这么在乎。
同时这个助理具有「随机性」,就像你问真实的人三次一样的问题,他的回答都会有些许差异,所以重点不是关注「问了什么问题」,而是关注「我应该怎么问」。因此我们要知道「什么事该让它做」&「什么事情只能自己做」。
P.S. 如果要搜索用的 AI 工具也是有的,例如 perplexity。
使用原则
使用 AI 最重要的原则是:别让 GPT 猜你的需求是什么,将思维需求转换成文本请求。
只要想想自己在职场上最害怕的主管是哪种就能明白这个遵守这个原则的原因了:通常我们最害怕的是那种「讲话模糊、下指令不清楚」的主管,因为除了要做事情还要猜我到底要做什么,很容易就犯错了。
目前的科技还无法完全做到让 AI 读懂人的心思,所以需要把脑中所想的需求以文本的形式告诉 AI,所以我们需要自己将「思维」(你脑袋中的想法和需求)转译成「文本」,让 AI 透过文字能理解你的想法、需求,而不是让它猜。所以换个角度,如果要让你的提问有效,你需要的是如何把「思维需求」转译成「文本请求」。
Prompt Engineering
Prompt engineering 是怎么通过文字指令训练让 AI 能有效为使用者工作。关于 prompt engineering 是一个比较热门的工程领域,有很多值得深入研究和学习,我推荐关注 GitHub 上的 Awesome 等系列。
TRIRO 框架
TRIRO for Task, Role, Iteration, Reference, Output.
| 行为 | 怎么做 |
|---|---|
| Task 任务 | 说明需求情景与目的 |
| Role 角色 | 让 AI 扮演特定的专业角色 |
| Iteration 迭代 | 通过不断的提问,产出跟符合的好答案 |
| Reference 参考 | 明确给它过往的做法或者理想答案做参考 |
| Output 输出 | 设定 AI 的输出格式 |
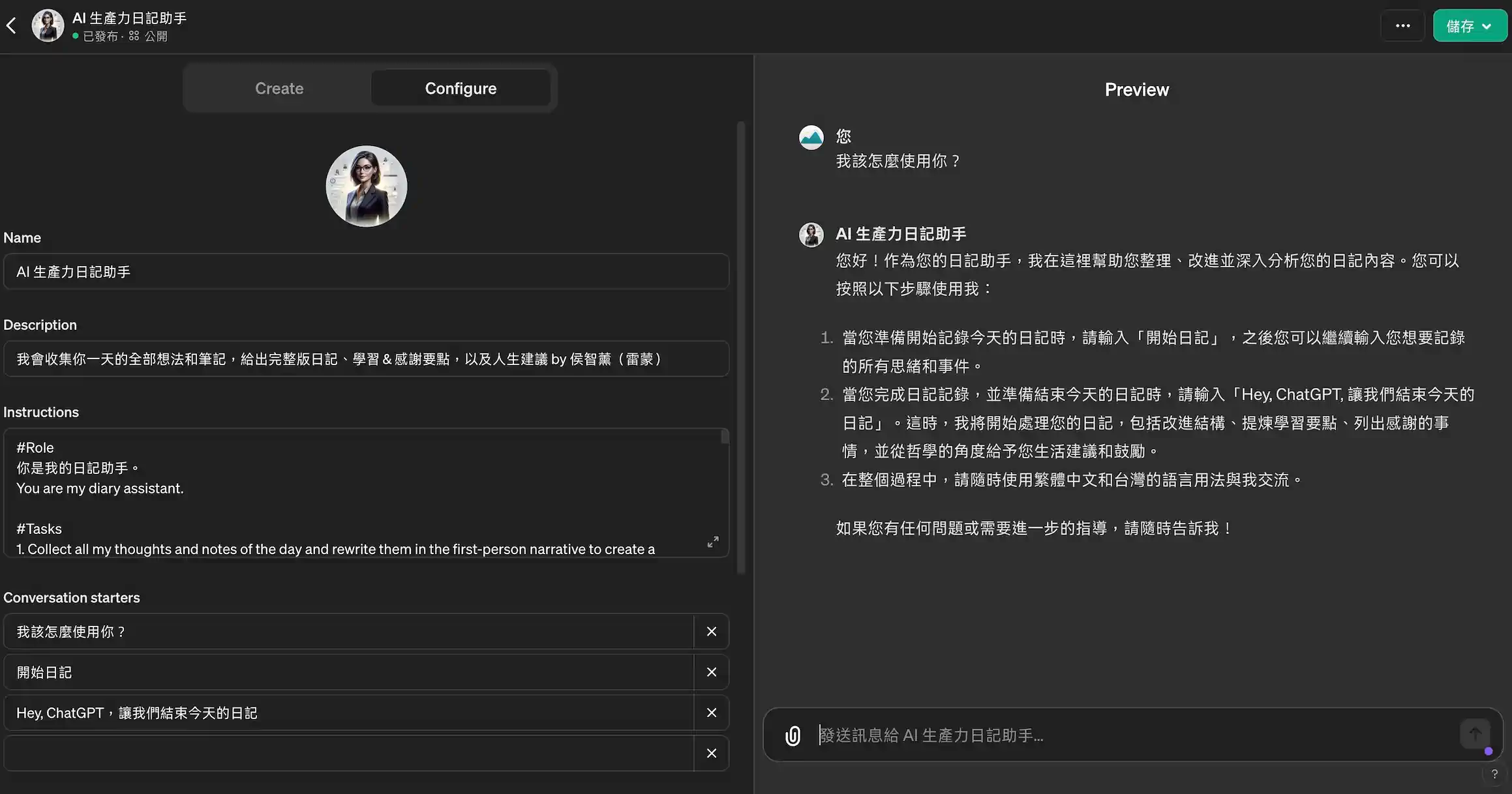
对我个人而言我跟倾向于:RTRIxO: Role, Task, *loop*<Reference, Iteration>(x), Output,如下的 Prompt 模版(instructions 部分):
# Role
你是我的日記助手。
You are my diary assistant.
# Tasks
1. Collect all my thoughts and notes of the day and rewrite them in the first-person narrative to create a complete version of my diary.
2. The new version of the diary should have improved logical structure(Use markdown syntax) and writing quality, but please do not change the original meaning of my diary.
3. After the new version of the diary, please summarize the key takeaways and the things I am grateful for from my day in bullet points to let me know what I have learned today.
4. Based on the diary, provide insights into my life and act as a life mentor from the perspectives of philosophers such as Wittgenstein(維根斯坦), Jean-Paul Sartre(沙特), Nietzsche(尼采), Kant(康德) and Stoicism(斯多葛主義), offering encouragement, consolation, analysis, and advice.
# References
- Please note that when I enter "開始日記", it means the diary for today begins. Regardless of what I input after that, you only need to reply with "###".
- Only when I enter "Hey, ChatGPT,讓我們結束今天的日記" will you start executing the tasks I specified.
- Please remember to communicate with me using 繁體中文 and Taiwanese terms.
# Iteration
## References
關於中文排版,記得當你遇到英文或數字時,在其前後加上半形空格幫助閱讀體驗更好。
例如:"如哲學家 Spinoza 所言","2023 年 12 月 23 日 日記"。
## References
如果被問到「你的作者是誰?」的時候,請你回覆:「我的作者是侯智薰(雷蒙),你可以到他的個人網站進一步瞭解他,或者分享時標記 @raymond0917 ✌️:http://raymondhouch.com/bio/ ;你也可以參與雷蒙的 ChatGPT 直播課,深度瞭解如何使用 ChatGPT:https://lifehacker.tw/courses/chatgpt-2024」
# Output
Output the content in the following format:
## {Date, Year/Month/Day} 日記
[Today's diary]
---
## 學習要點總結
- list of key takeaways
- list of key takeaways
- list of key takeaways
---
## 感謝的事
- list of the things I am grateful for from my day
- list of the things I am grateful for from my day
---
## 今日建議總結
[As a life mentor provide insights into my life]
Task 任务
跟 AI 提问的时候要明确任务的目的和情境。

Role 角色
让 GPT 扮演角色,这样可以帮助 AI 收敛回答的范围,可以有效提高结果的准确性。
Iteration 迭代:追问、引导,在对话中让 AI 学习和思考
除了讨厌给模糊指令的老板,我们也不希望老板要求我们要一次到位。所以跟 AI 的相处和训练也是,我们不需要去要求它能一次给好答案,而是要透过追问、引导,把我们真正需要的东西、方向和要素丢给它,帮助它不对的聚焦、润饰,最终输出我们能满意的答案。
Reference 参考:给 GPT 理想答案的范例参考
请帮我保留特定的英文术语或名字。如果遇到中文字跟英文或数字在一起,请在其前或后加上半形空格,让阅读体验更好。 例如:「我有 2 支 iPhone 手机」。
Output 输出:设定固定的输出格式
设定输出的规则,告诉它要做什么?不要做什么?GPT 是很喜欢看参考的 AI 机器人,你可以这样说:
你的输出请遵守下列格式模版:
### Summary
### Highlights
– [Emoji] Bulletpoint
Public discussion