
小本本系列:大模型中的向量嵌入Vector embeddings

Vector embeddings are a method to convert non-structured data, such as text, images, and videos, into numerical representations that capture their meanings and relationships. This allows computers, which only understand numbers, to process and interpret these data more effectively. Embeddings are crucial for tasks like semantic similarity and are used in various AI models, including LLMs, RAG, and multimodal processing.
vector embeddings 的感性理解
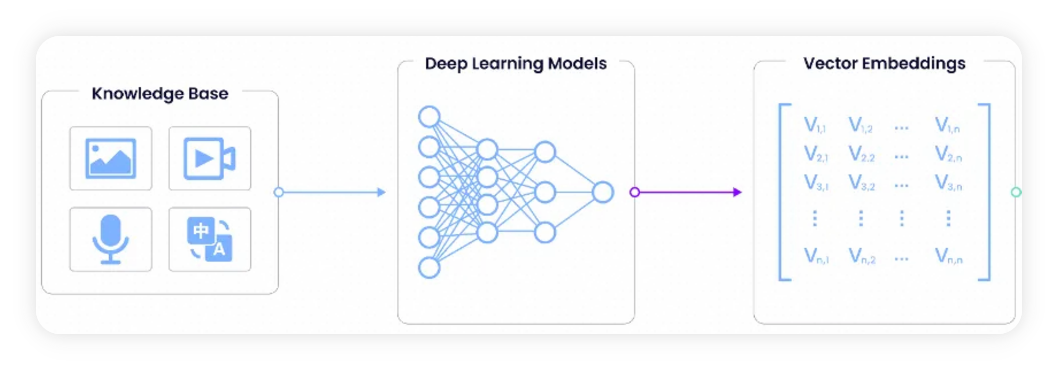
vector embeddings 的出现最本质的原因是科学家为了解决一个问题 —— 让只认识0、1数字,只会做逻辑运算和浮点运算的计算机,能够理解人类语言、文字、图像、视频等数据包含的语义以及它们之间的关系。例如,「泰迪」、「狗」、「犬」、「哺乳动物」这几个单词在不同的上下文中其实是同一个意思,即一种四足、有尾巴、有尖牙的哺乳动物,这就是文字、图像、视频中包括的语义信息,科学家希望计算机可以理解这些。
既然计算机只认识数字,只会做运算,科学家的想法很直接,那就我们就将人类使用的文字、句子、文章、书本、图像、视频等等非结构化的数据转换成数字来描述,帮助计算机高效的理解和处理它们,于是就有了 vector embeddings。
vector embeddings 是什么
vector embeddings(向量嵌入)是一种将单词、句子和其他数据转换为数字的方法,这些数字捕获了它们的含义和关系。它们将不同类型的数据表示为高维空间(多维空间)中的点,其中相似的数据点聚集在一起。这些数值表示有助于机器更有效地理解和处理这些数据。
向量嵌入在处理语义相似度时至关重要。vector(向量)仅仅是一系列数字;vector embedding(向量嵌入)是一系列代表输入数据的数字。通过使用 vector embeddings,我们可以结构化非结构化数据或通过将其转换为一系列数字来处理任何类型的数据。这种方法使我们能够对输入数据执行数学运算,而不是依赖定性比较。
vector V.S. embedding
在 vector embeddings (向量嵌入)的上下文中,embedding(嵌入)和 vector(向量)是同一回事。两者都指数据的数值表示,其中每个数据点都由高维空间中的向量表示。
“vector 向量”仅指具有特定维数的数字数组。在 vector embedding(向量嵌入)的情况下,这些向量表示上述任何数据点在一个连续的空间中。
“embedding 嵌入”专门指将数据表示为 vector(向量)的技术,以捕获有意义的信息、语义关系或上下文特征。embedding 嵌入旨在捕获数据的底层结构或属性,通常通过训练算法或模型来学习。
虽然嵌入和向量可以在向量嵌入的上下文中互换使用,“嵌入”强调以有意义和结构化的方式表示数据的概念,而“向量”则指数值表示本身。
如何构建 vector embeddings
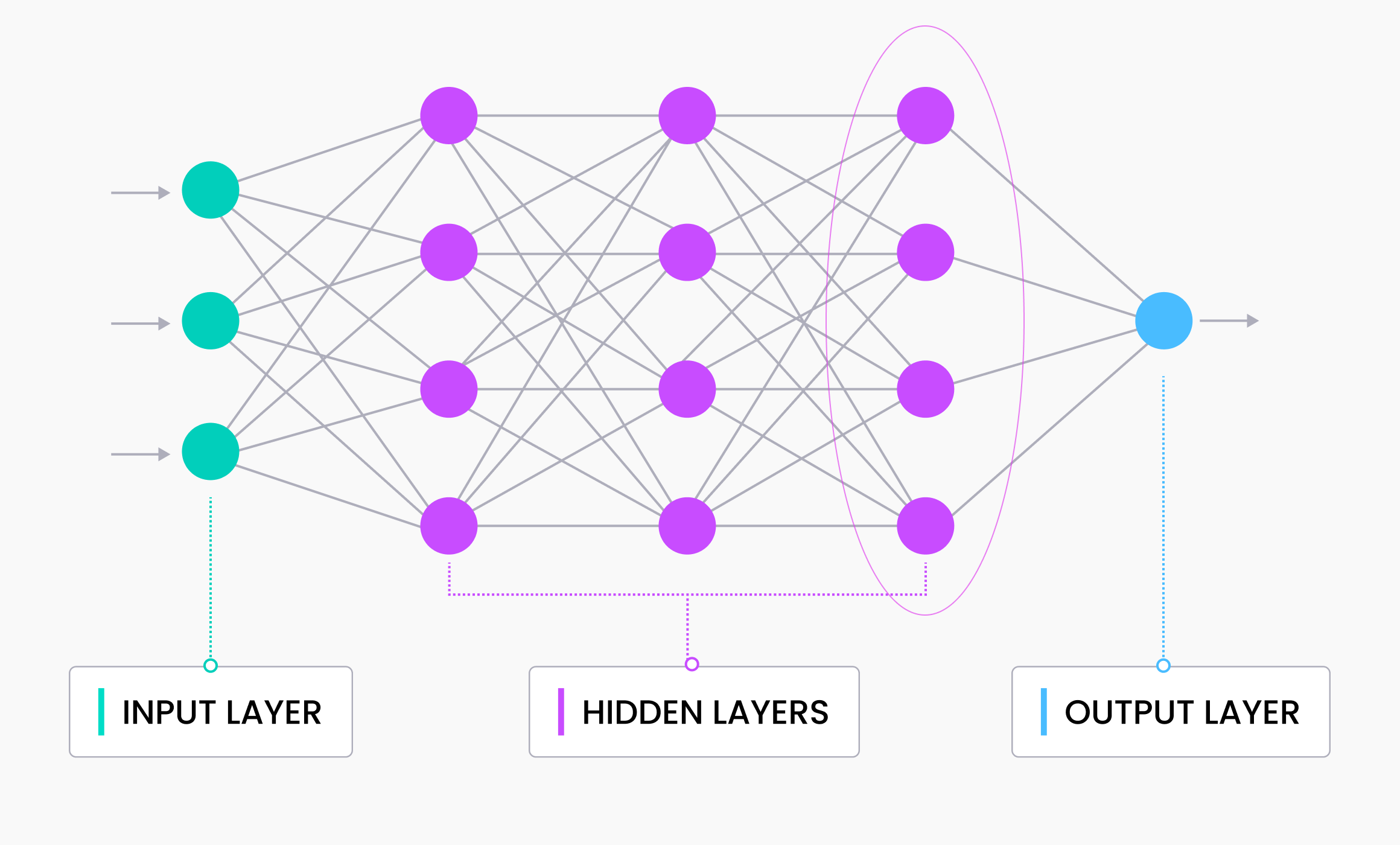
vector embeddings 是深度学习模型中输入数据的内部表示,也称为嵌入模型或深度神经网络。那么,我们如何提取这些信息呢?
我们通过移除最后一层并从倒数第二层获取输出,来获得 vector 向量。神经网络的最后一层通常输出模型的预测,因此我们取倒数第二层的输出。vector embedding(向量嵌入)是馈送到神经网络预测层的数据。
vector embedding(向量嵌入)的维数等于模型中倒数第二层的尺寸,因此与向量的尺寸或长度可互换。常见的向量维数包括384(例如 Sentence Transformers Mini-LM 生成的 vector)、768(例如 Sentence Transformers MPNet 生成的 vector)、1,536(例如 OpenAI 生成的 vector)和2,048(例如 ResNet-50 生成的 vector)。
奇怪的 vector embeddings 维数 768、1024、1536、2048
最早的 GPT-2 设置中,头的数量是 12(dimension heads),它可以整除 768。
这个数字来自于超参数优化(hyperparameter optimization)。使用 4096 大小的嵌入和 1 层的神经网络,或者使用 16 大小的嵌入和 2B 参数的神经网络是没有意义的,这些值之间需要一个良好的平衡。
那么为什么是 768 而不是 769 呢?我们通常使用 2 的幂(或接近的值)来尝试超参数,因为它们在计算上更快,并且更适合 GPU 内存分配(就像你的屏幕分辨率一样,GPU 只是一个计算矩阵的大型机器)。768 = 512 + 256 = 2**9 + 2**8。
vector embeddings 维度的含义
我曾经查找资料并试图弄懂 vector embeddings(向量嵌入)中每个维度的含义。最终的答案是,单个维度没有任何意义。vector embeddings 中的单个维度过于抽象,无法确定其含义。然而,当我们将所有维度放在一起时,它们提供了输入数据的语义含义。
向量的维度是不同属性的高级抽象表示。表示的属性取决于训练数据和模型本身。文本和图像模型生成不同的嵌入,因为它们针对根本不同的数据类型进行训练。即使是不同的文本模型也会生成不同的嵌入。有时它们在大小上不同;其他时候,它们在表示的属性上不同。例如,在法律数据上训练的模型将学习与在医疗保健数据上训练的模型不同的事物。
图像 vector embeddings
2012 年 AlexNet 的出现标志着图像识别技术的飞跃。自那时以来,计算机视觉领域取得了无数进展。最新的知名图像识别模型是 ResNet-50,它是一个基于前代 ResNet-34 架构的 50 层深度残差网络。
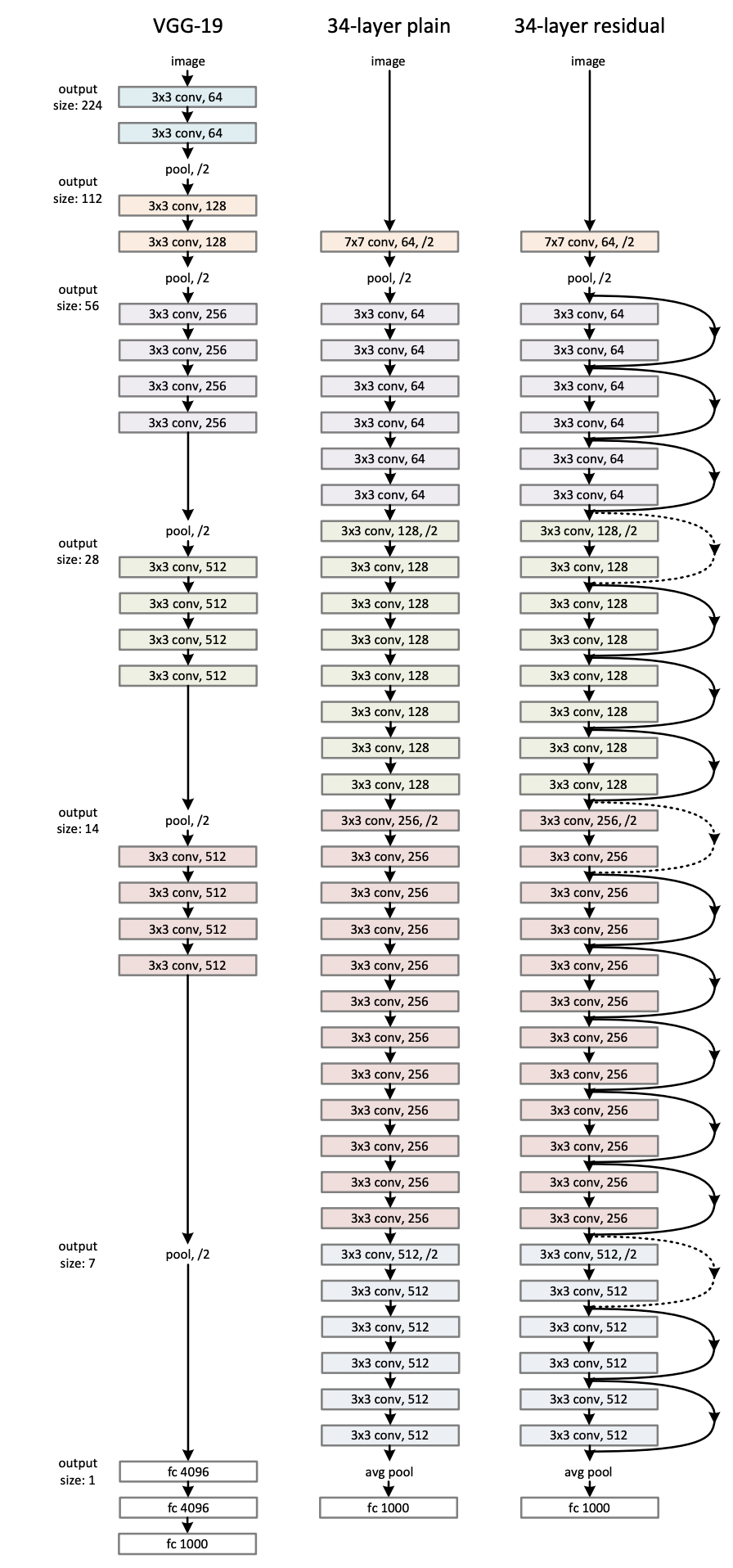
尝试使用 microsoft/resnet-50 · Hugging Face生成图像的 vector embeddings:
# Load model directly
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
from PIL import Image
extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-50")
model = AutoModelForImageClassification.from_pretrained("microsoft/resnet-50")
image = Image.open("<image path>")
# image = Resize(size=(256, 256))(image)
inputs = extractor(images=image, return_tensors="pt")
# print(inputs)
outputs = model(**inputs)
vector_embeddings = outputs[1][-1].squeeze()
文本 vector embeddings
人工智能对自然语言的处理已经从基于规则的嵌入发展到了一个新的高度。从最初的神经网络开始,我们通过 RNN 添加了递归关系来跟踪时间步长。从那时起,我们使用 Transformer 来解决序列转导问题。
Transformer 由编码器、注意力矩阵和解码器组成。编码器将输入编码为表示状态的矩阵,注意力矩阵和解码器对状态和注意力矩阵进行解码,以预测正确的下一个标记来完成输出序列。GPT 是迄今为止最流行的语言模型,它由严格的解码器组成。它们对输入进行编码并预测正确的下一个标记。
尝试使用 sentence-transformers生成文本的 vector embeddings:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("<model-name>")
vector_embeddings = model.encode(“<input>”)
多模态 vector embeddings
以图生文为例,使用开源模型 CLIP VIT 来生成 embeddings:
# Load model directly
from transformers import AutoProcessor, AutoModelForZeroShotImageClassification
processor = AutoProcessor.from_pretrained("openai/clip-vit-large-patch14")
model = AutoModelForZeroShotImageClassification.from_pretrained("openai/clip-vit-large-patch14")
from PIL import Image
image = Image.open("<image path>")
# image = Resize(size=(256, 256))(image)
inputs = extractor(images=image, return_tensors="pt")
# print(inputs)
outputs = model(**inputs)
vector_embeddings = outputs[1][-1].squeeze()
语音 vector embeddings
以语音生成文字为例,使用开源模型 Whisper 模型来获取 embedding:
import torch
from transformers import AutoFeatureExtractor, WhisperModel
from datasets import load_dataset
model = WhisperModel.from_pretrained("openai/whisper-base")
feature_extractor = AutoFeatureExtractor.from_pretrained("openai/whisper-base")
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
inputs = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt")
input_features = inputs.input_features
decoder_input_ids = torch.tensor([[1, 1]]) * model.config.decoder_start_token_id
vector_embedding = model(input_features, decoder_input_ids=decoder_input_ids).last_hidden_state
视频 vector embeddings
视频的 embeddings 比语音、图片的 embeddings 更加复杂,它需要多模态的处理来保证语音与图片的同步,以 DeepMind 开源模型 multimodal perceiver 为例生成视频的 vector embeddings(注意代码 outputs[1][-1].squeeze()):
def autoencode_video(images, audio):
# only create entire video once as inputs
inputs = {'image': torch.from_numpy(np.moveaxis(images, -1, 2)).float().to(device),
'audio': torch.from_numpy(audio).to(device),
'label': torch.zeros((images.shape[0], 700)).to(device)}
nchunks = 128
reconstruction = {}
for chunk_idx in tqdm(range(nchunks)):
image_chunk_size = np.prod(images.shape[1:-1]) // nchunks
audio_chunk_size = audio.shape[1] // SAMPLES_PER_PATCH // nchunks
subsampling = {
'image': torch.arange(
image_chunk_size * chunk_idx, image_chunk_size * (chunk_idx + 1)),
'audio': torch.arange(
audio_chunk_size * chunk_idx, audio_chunk_size * (chunk_idx + 1)),
'label': None,
}
# forward pass
with torch.no_grad():
outputs = model(inputs=inputs, subsampled_output_points=subsampling)
output = {k:v.cpu() for k,v in outputs.logits.items()}
reconstruction['label'] = output['label']
if 'image' not in reconstruction:
reconstruction['image'] = output['image']
reconstruction['audio'] = output['audio']
else:
reconstruction['image'] = torch.cat(
[reconstruction['image'], output['image']], dim=1)
reconstruction['audio'] = torch.cat(
[reconstruction['audio'], output['audio']], dim=1)
vector_embeddings = outputs[1][-1].squeeze()
# finally, reshape image and audio modalities back to original shape
reconstruction['image'] = torch.reshape(reconstruction['image'], images.shape)
reconstruction['audio'] = torch.reshape(reconstruction['audio'], audio.shape)
return reconstruction
return None
Public discussion