
Agentic AI

What
AI Agent 当前还是一个比较新兴的基于 LLM 的概念,Google 最近发布了关于它的白皮书(Agents | Kaggle),最近我看到一个说法:「AI 是风口,AI Agent则是风口的平方」,所以我打算结构性的梳理一下 AI Agent 的概念。
我个人粗浅地将 AI Agent 分为两个层次 Generative AI Agent 和 Agentic AI:
- Generative AI Agent,当前经常提到的 AI Agent 大多是指 Generative AI Agent,它将推理(Reasoning)、逻辑(Logic)和对外部信息的访问(External Info Access)都与生成式人工智能模型(LLM)相联系,从而形成了 Agent 的概念,或者说是一个超出生成式人工智能模型(LLM)独立功能的应用。
- Agentic AI,Agentic AI 也被称为 Agentic Systems,它是指能够自主行动来实现目标而无需有人介入的系统和模型。Agentic AI 系统了解用户的目标以及他们试图解决的问题的背景,并可以主动为解决问题进行推理和行动。
由于 AI Agent 发展还在早期,Agentic AI 目前还是大家对 AI Agent 终态的美好想象,所以本文主要就先梳理清楚 Generative AI Agent,后面提到的 AI Agent 均指 Generative AI Agent。
技术架构
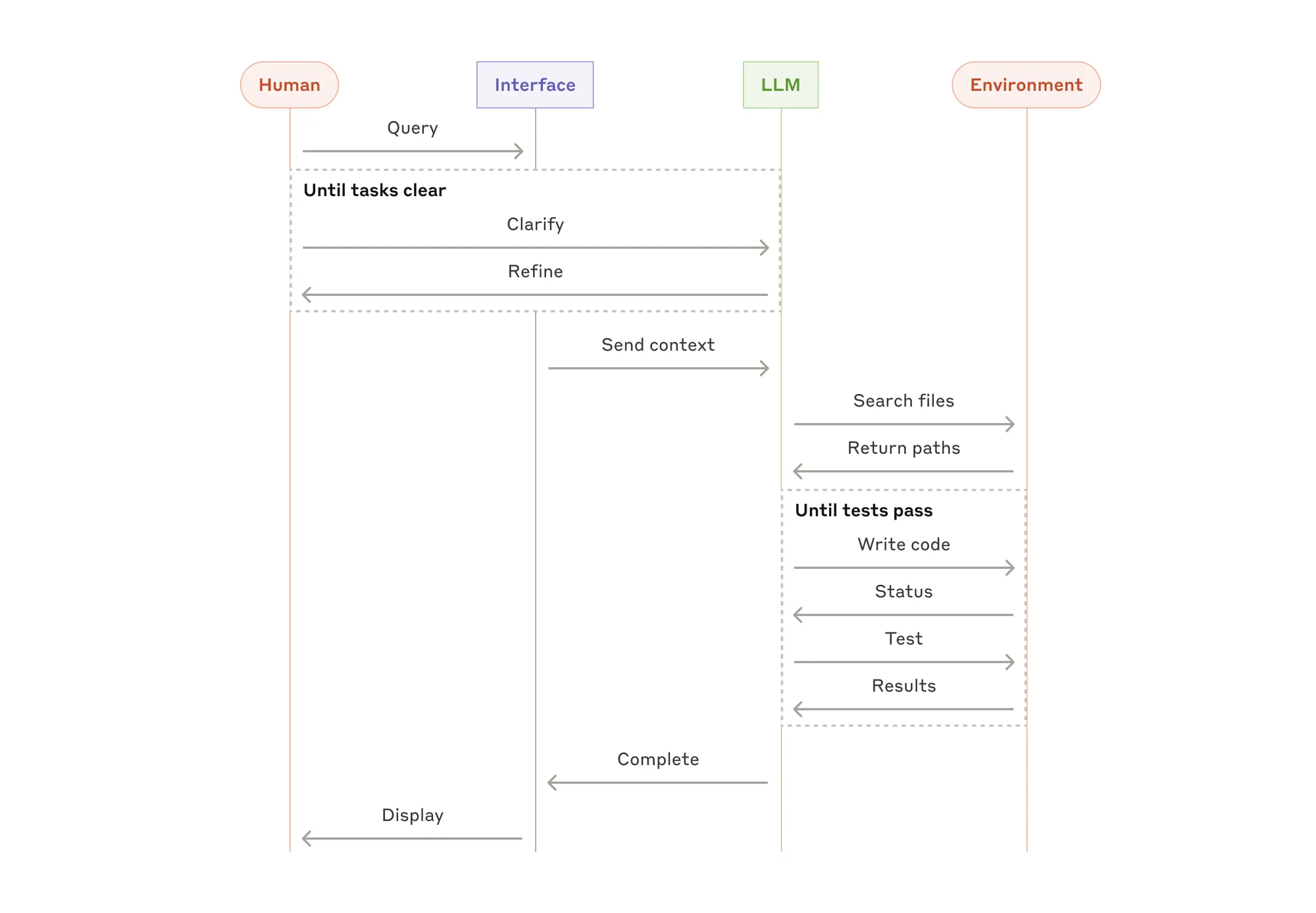
为了理解 AI Agent 的内部工作原理,我们首先介绍 AI Agent 运行和决策的基础组件。这些组件的组合可以描述为认知架构(cognitive architecture),并且可以通过混合和匹配这些组件来实现许多这样的架构。专注于核心功能,Agent 的认知架构中有三个基本组件,如下图所示。
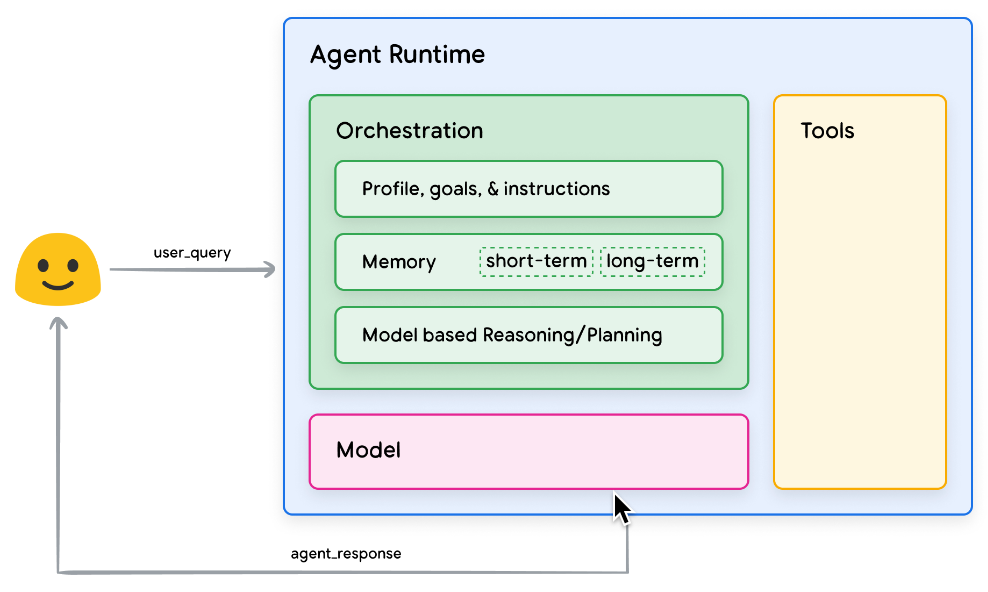
- Model,AI Agent 架构中的 model 模型是指将用作 Agent 流程的集中决策者的语言模型 (LM),通常是指 claude、gemini、chatgpt 等 LLM。
- Tools,由于 Model 受到无法与外界互动的限制,所以需要 tools 工具来弥补这一缺陷,tools 使得 Agent 能够与外部数据和服务进行交互,从而解锁和释放模型 LLM 的能力。
- Orchestration Layer,编排层描述了一个循环过程,它控制着 AI Agent 如何获取信息、执行一些内部推理,并使用该推理来指导其下一步行动或决策。
Workflow V.S. Agent
了解完 AI Agent 的技术架构之后,其实会有一个疑惑:「从架构来看 AI Agent 就是在 LLM 的基础上增加了与外部交互的工作流,为什么它会被提到如此高的地位?」。
对于这个疑问我想先对比一下 workflows 和 agents:
- Workflows,是通过预定义的代码路径来协调 LLM 和工具的系统
- Agents,是 LLM 动态指导其自身流程和工具使用的系统,从而控制其完成任务的方式
Agent 与 Workflow 最大的区别就是 Agent 可以使用认知架构(Cognitive Architecture)来实现其最终目标,方法是迭代处理信息、做出明智的决策并根据先前的输出完善下一步行动。Agent 认知架构的核心是编排层,负责维护记忆、状态、推理和规划。它使用快速发展的即时工程领域和相关框架来指导推理和规划,使 Agent 能够更有效地与其环境交互并完成任务,例如使用 LLM 的 ReAct、CoT、ToT 等推理技术来根据任务目标选择行为和工具。
Agent 常见的模式
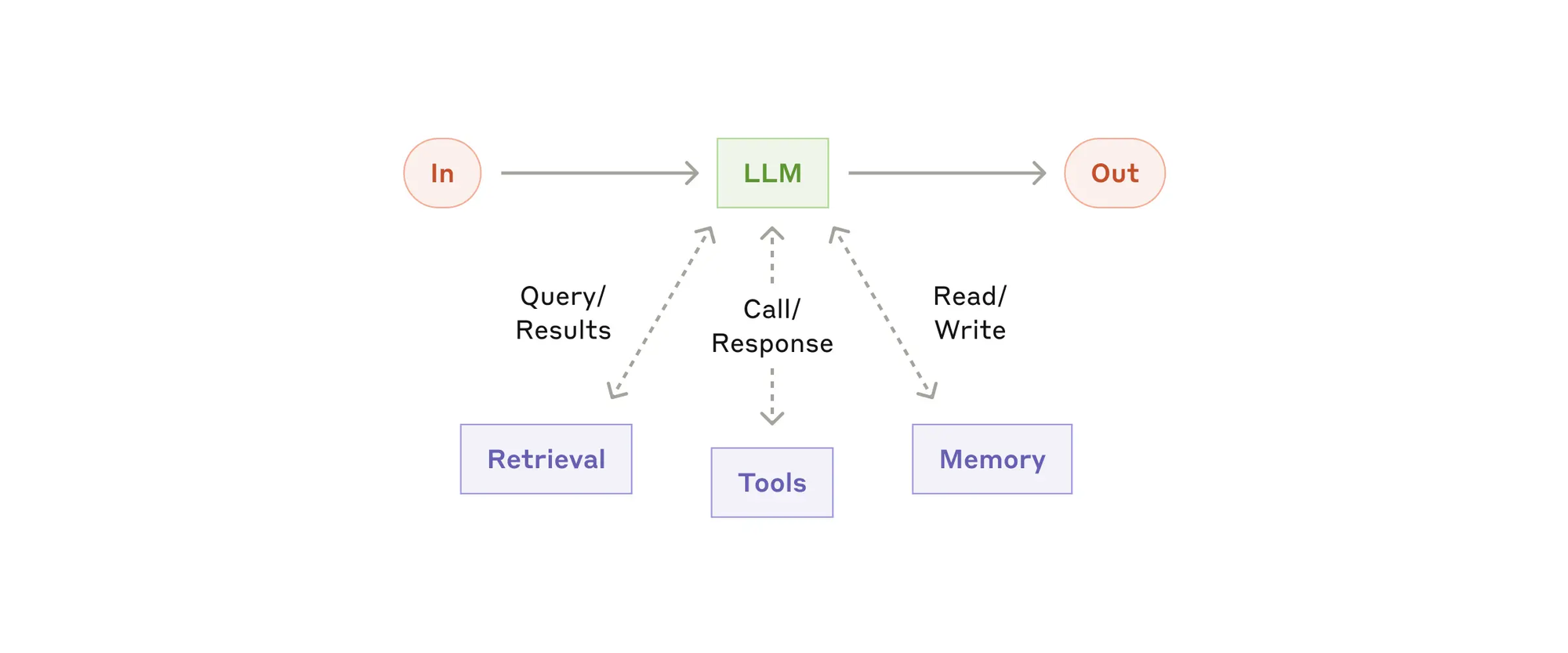
- The augmented LLM(增强型 LLM),增强的LLM,增强了检索、工具和记忆等功能。我们当前的模型可以主动使用这些功能——生成自己的搜索查询,选择适当的工具,并确定要保留的信息。
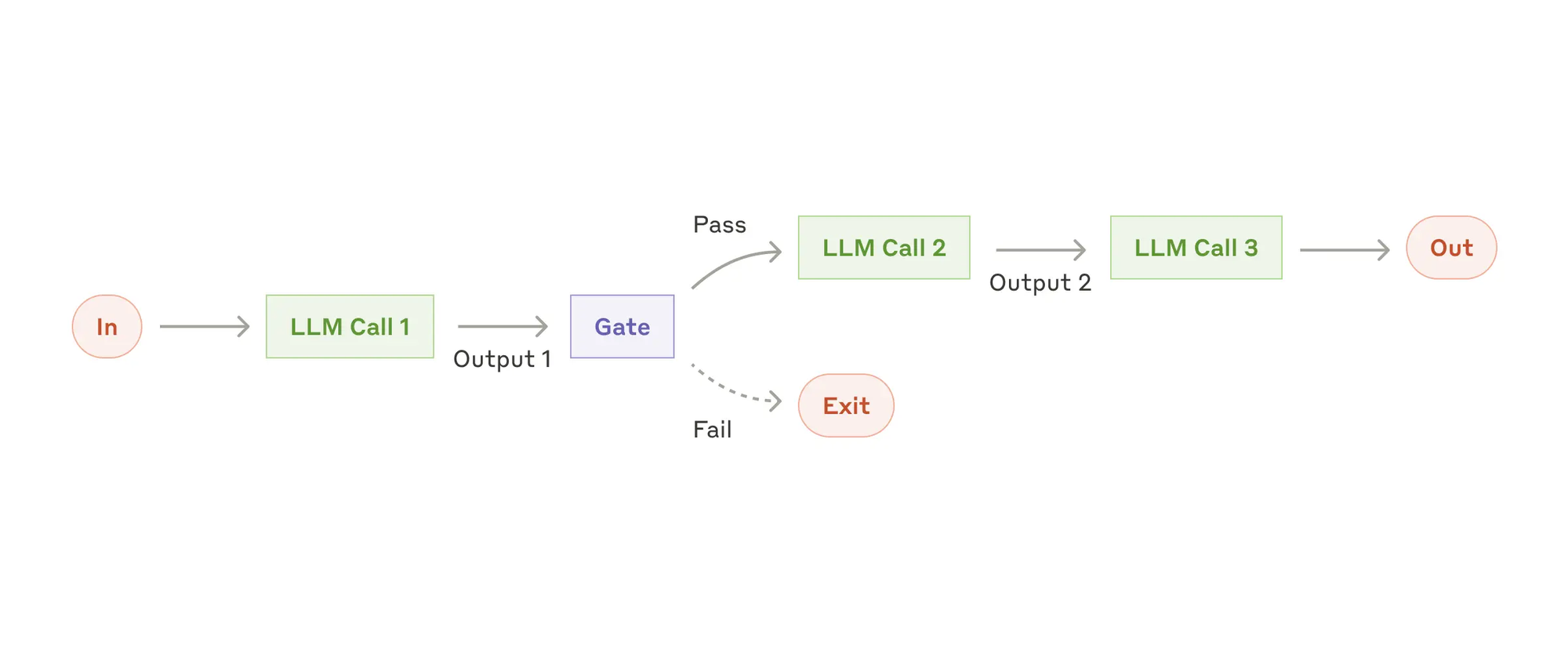
- Prompt chaining(提示链),提示链将任务分解为一系列步骤,其中每个LLM调用处理前一个的输出。你可以在任何中间步骤添加程序检查(参见下图中的“门”)以确保过程仍在正轨上。何时使用此工作流: 此工作流非常适合可以轻松且清晰地分解为固定子任务的情况。主要目标是通过使每个 LLM 调用变得更简单,以牺牲延迟来换取更高的准确性。
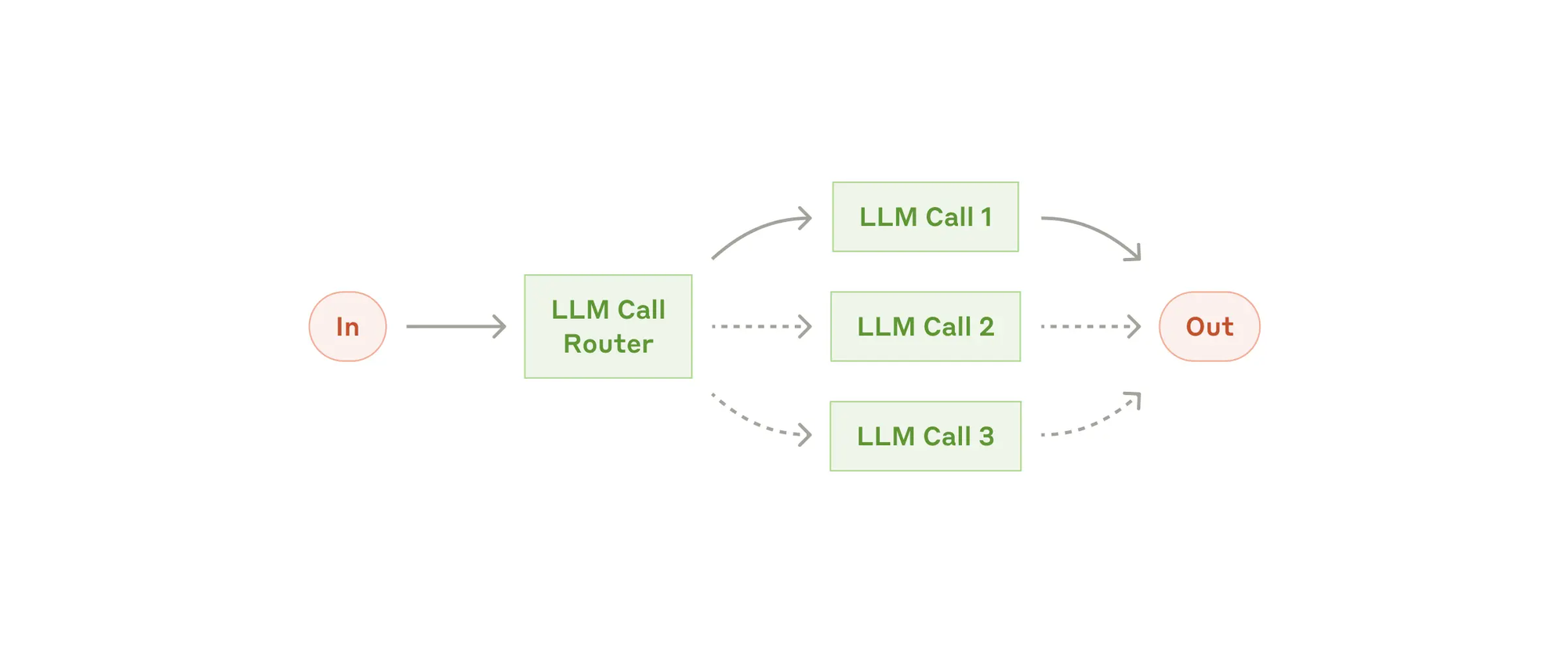
- Route(路由),路由对输入进行分类,并将其导向专门的后续任务。这种工作流程允许分离关注点,并构建更专业的提示。没有这种工作流程,优化一种输入可能会损害其他输入的性能。何时使用此工作流: 路由适用于复杂的任务,其中存在可以单独处理的明确类别,并且分类可以通过LLM或更传统的分类模型/算法准确处理。
- Parallelization(并行化),LLMs 有时可以同时处理一个任务,并通过编程方式聚合它们的输出。何时使用此工作流程: 当可以将子任务并行化以提高速度,或者需要多个视角或尝试以获得更可靠的结果时,并行化是有效的。对于具有多个考虑因素的复杂任务,LLMs 通常在每个考虑因素由单独的 LLM 调用处理时表现更好,从而能够专注于每个具体方面。这种工作流程,即并行化,表现为两种主要变体:
- Sectioning(分块):将任务分解为独立的子任务并行运行。
- Voting(投票): 多次运行相同任务以获得多样化的输出。
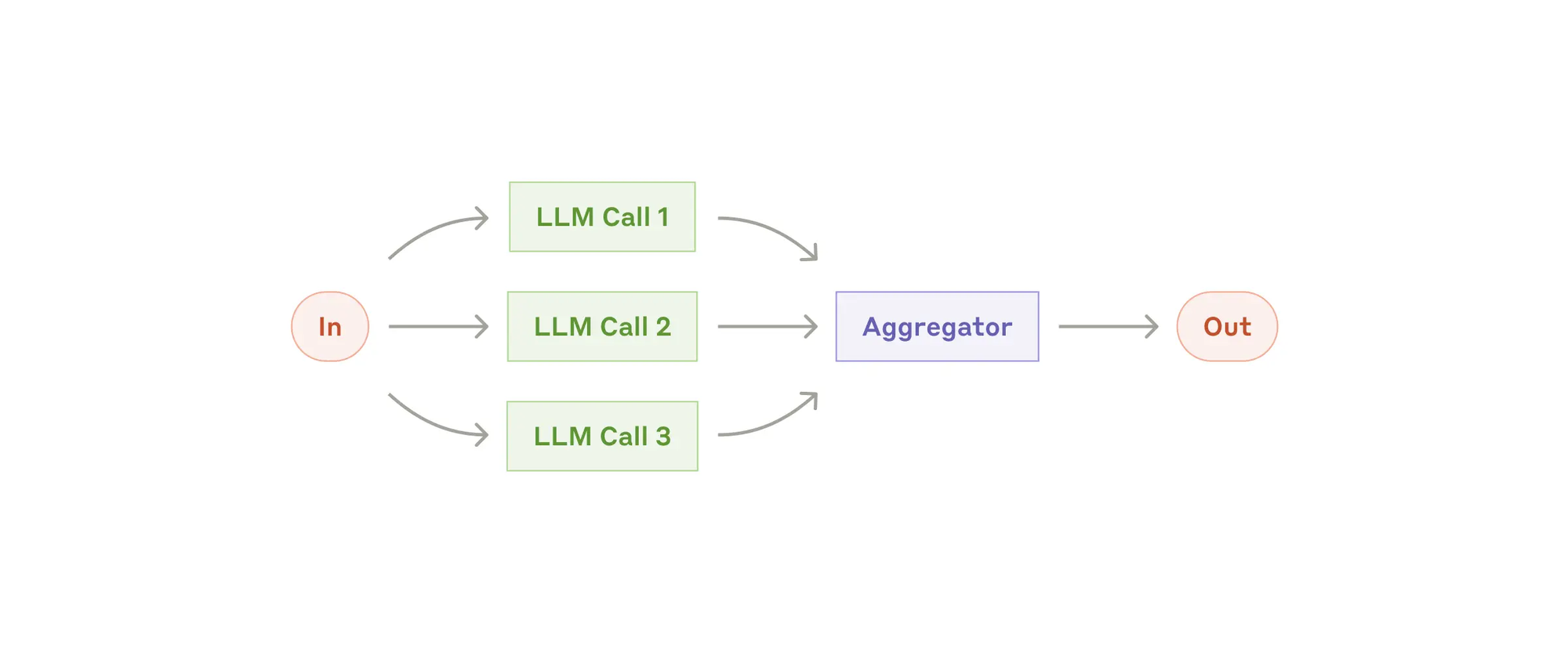
- Orchestrator-workers(编排者-工作者),在编排者-工作者工作流中,中央LLM动态地分解任务,将它们委派给工作者LLMs, 并合成其结果。何时使用此工作流:此工作流非常适合复杂的任务,您无法预测所需的子任务(例如在编程中,需要更改的文件数量和每个文件中的更改性质可能取决于任务)。虽然它在拓扑上相似,但与并行化的主要区别在于其灵活性——子任务不是预先定义的,而是由协调者根据具体输入来确定。
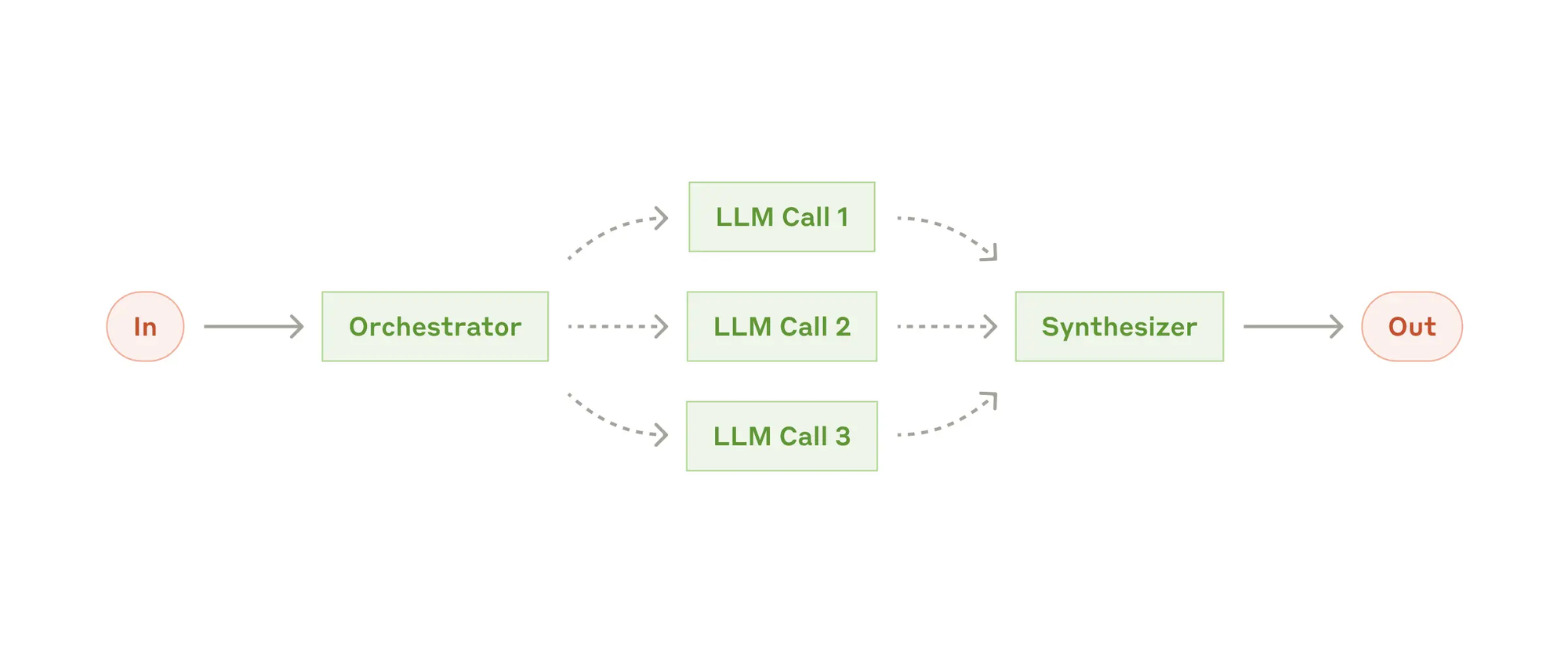
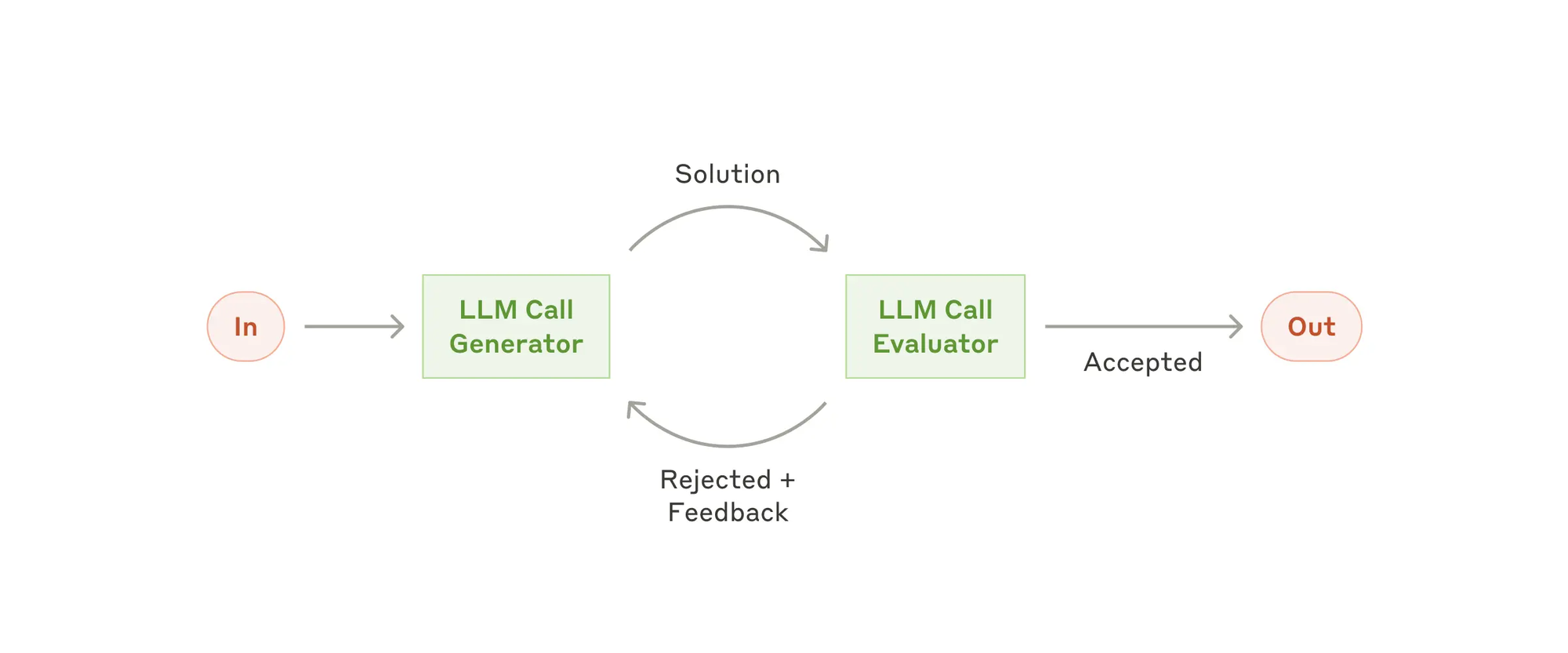
- Evaluator-optimizer(评估器-优化器),在评估器-优化器工作流中,一个 LLM 调用生成响应,而另一个则在一个循环中提供评估和反馈。何时使用此工作流: 当我们有明确的评估标准,并且迭代改进能够提供可衡量的价值时,此工作流特别有效。良好的适应性有两个标志,首先,当人类能够清楚地表达他们的反馈时,LLM 的响应可以明显改善;其次,LLM 能够提供此类反馈。这类似于人类作者在撰写一篇精心打磨的文档时所经历的迭代写作过程。
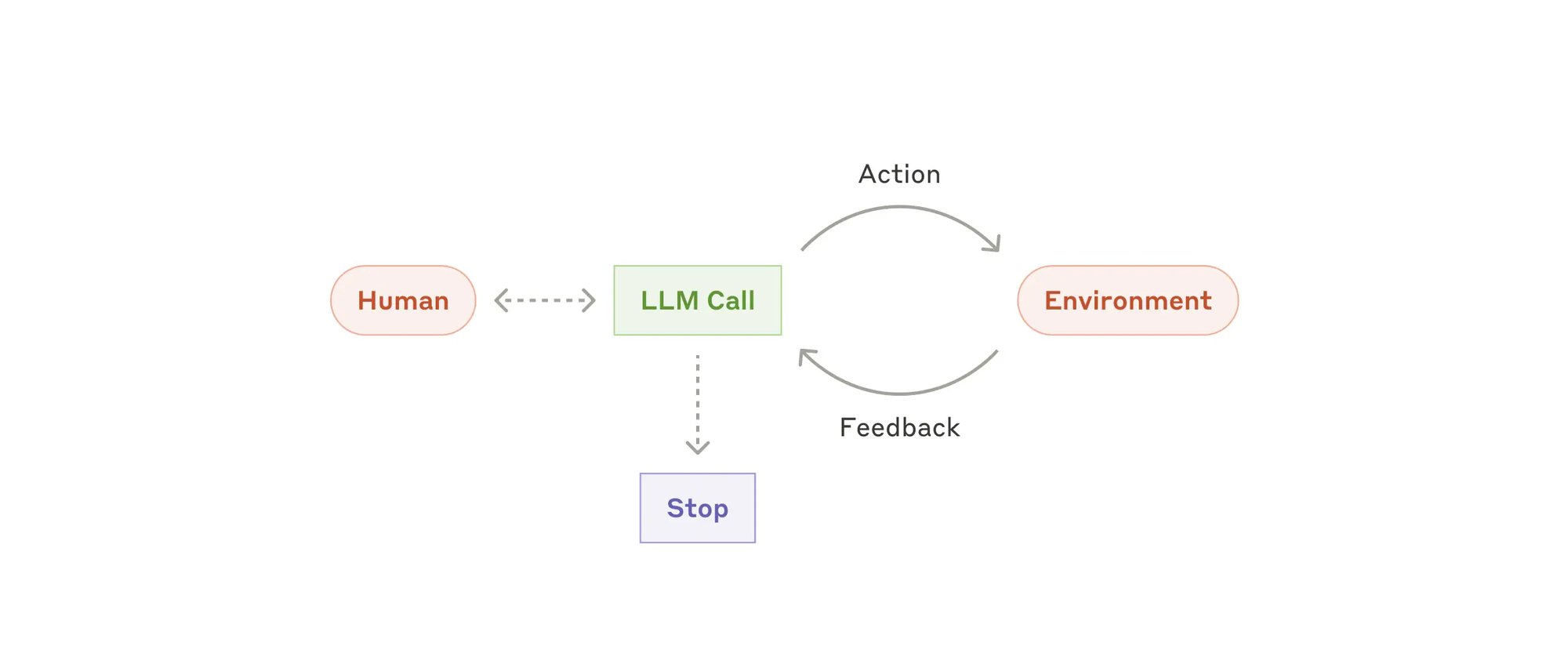
- Agents(智能体),随着 LLMs 在关键能力上逐渐成熟——理解复杂输入、进行推理和规划、可靠地使用工具以及从错误中恢复,agent 正在生产中出现。agent 的工作始于人类用户的命令或互动讨论。一旦任务明确,agent 将独立地进行计划和操作,必要时返回向人类用户寻求更多信息或判断。在执行过程中,agent 需要在每一步从环境中获取“真实情况”(如工具调用结果或代码执行)以评估其进展。然后,agent 可以在检查点或遇到阻碍时暂停以获得人类反馈。任务通常在完成后终止,但也常见设置停止条件(例如最大迭代次数)以保持控制。AI Agent 可以处理复杂的任务,但它们的实现通常很简单。它们通常是使用基于环境反馈的工具循环的 LLMs。因此,设计工具集及其文档时必须清晰且周到。何时使用 Agent:Agent 可以用于开放式问题,当难以或无法预测所需的步骤数量,并且无法硬编码固定路径时。LLM 可能会运行多个回合,您必须对其决策有一定的信任。AI Agent 的自主性使它们在受信任的环境中非常适合扩展任务
When
对程序员而言什么时候需要用到 AI Agent 呢?
在使用 LLMs 构建应用程序时,Claude 建议寻找最简单的解决方案,并且只在必要时增加复杂性。这可能意味着根本不需要构建 agentic system,agentic system 通常会在延迟和成本上做出妥协以换取更好的任务表现,您应该考虑这种权衡是否有意义。
当需要更多复杂性时,workflow 为明确定义的任务提供可预测性和一致性,而 agent 则是在需要大规模灵活性和模型驱动决策时的更好选择。然而,对于许多应用程序来说,通过检索和上下文示例优化单个 LLM 调用通常就足够了。
How
虽然语言模型 LLM 擅长处理信息,但它们缺乏直接感知和影响现实世界的能力,这限制了它们在需要与外部系统或数据交互的情况下的实用性。从某种意义上说,语言模型 LLM 的好坏取决于它从训练数据中学到的东西,但无论我们向模型投入多少数据,它们仍然缺乏与外界交互的基本能力,如何实现 tools 才能使我们的模型能够与外部系统进行实时、上下文感知的交互就是 AI Agent 需要做的第一件事情。
Google AI Agent 白皮书发布的时候,在技术架构中解决与外部系统交互和感知的方法包括:
- Functions
- Extensions
- Data Stores
Extensions
理解 AI Agent Extensions 的最简单方法是将其视为以标准化方式弥合 API 和 Agent 之间的差距,从而允许 Agent 无缝执行 API,而不管其底层实现如何。Extensions 通过以下方式弥合 AI Agent 与 API 之间的差距:
- 使用示例教 AI Agent 如何使用 API
- 教AI Agent 成功调用 API 端点所需的参数

Extension 示例:
import vertexai
import pprint
PROJECT_ID = "YOUR_PROJECT_ID"
REGION = "us-central1"
vertexai.init(project=PROJECT_ID, location=REGION)
from vertexai.preview.extensions import Extension
extension_code_interpreter = Extension.from_hub("code_interpreter")
CODE_QUERY = """Write a python method to invert a binary tree in O(n) time."""
response = extension_code_interpreter.execute(
operation_id = "generate_and_execute",
operation_params = {"query": CODE_QUERY})
print("Generated Code:")
pprint.pprint({response['generated_code']})
# The above snippet will generate the following code.
# Generated Code:
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
def invert_binary_tree(root):
"""
Inverts a binary tree.
Args:
root: The root of the binary tree.
Returns:
The root of the inverted binary tree.
"""
if not root:
return None
# Swap the left and right children recursively
root.left, root.right = invert_binary_tree(root.right), invert_binary_tree(root.left)
return root
# Example usage:
# Construct a sample binary tree
root = TreeNode(4)
root.left = TreeNode(2)
root.right = TreeNode(7)
root.left.left = TreeNode(1)
root.left.right = TreeNode(3)
root.right.left = TreeNode(6)
root.right.right = TreeNode(9)
# Invert the binary tree
inverted_root = invert_binary_tree(root)
Functions
Functions 就是被预先定义好的独立的代码模块,可以完成特定任务,并可根据需要重复使用。LLM 可以采用一组已知的 Functions,并根据其规范决定何时使用每个函数以及函数需要哪些参数。
Functions 与 Extensions 比较类似,但也有几个不同之处:
- LLM 输出 Functions 及其参数,但不进行实时 API 调用,调用实际 API 的逻辑和执行将从 Agent 转移回 Client
- Functions 在 Client 执行,而 Extensions 在 Agent 执行
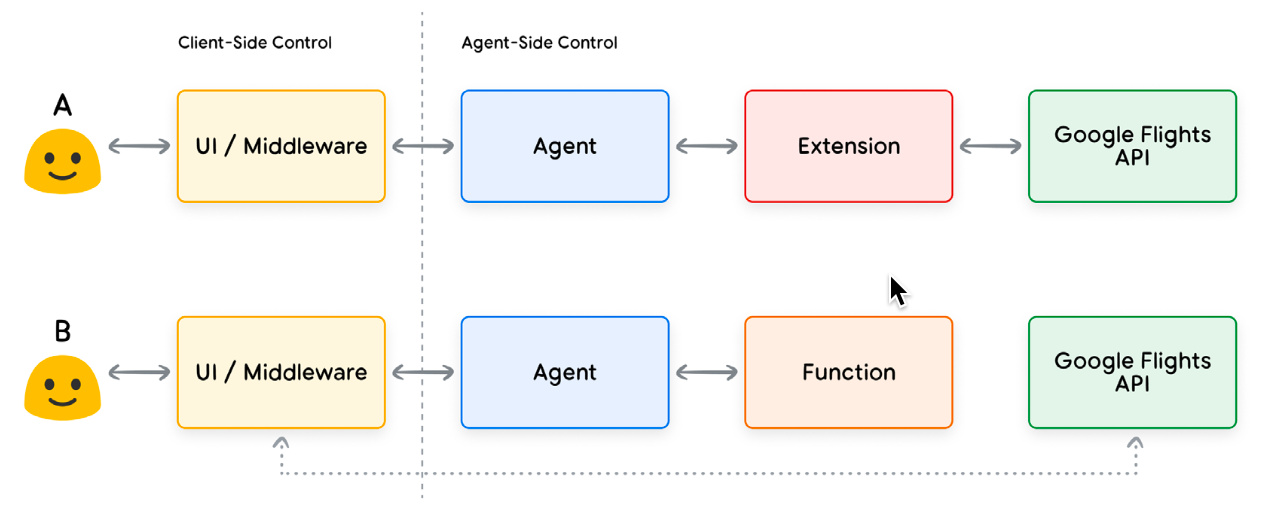
开发人员选择使用函数而不是扩展的原因有很多,但一些常见的用例是:
- API 调用需要在应用程序堆栈的另一层进行,在 AI Agent 架构流程之外(例如中间件系统、前端框架等)
- 安全或身份验证限制阻止 Agent 直接调用 API(例如 API 未暴露给互联网,或基础设施无法访问)
- 时间或操作顺序限制阻止 Agent 实时进行 API 调用(即批量操作、人工审核等)
- 需要将 Agent 无法执行的额外数据转换逻辑应用于 API 响应(例如,考虑一个不提供过滤机制来限制返回结果数量的 API 端点。在客户端使用函数为开发人员提供了进行这些转换的额外机会。)
- 开发人员希望在不为 API 端点部署额外基础设施的情况下迭代 Agent 开发(即函数调用可以充当 API 的“存根”)
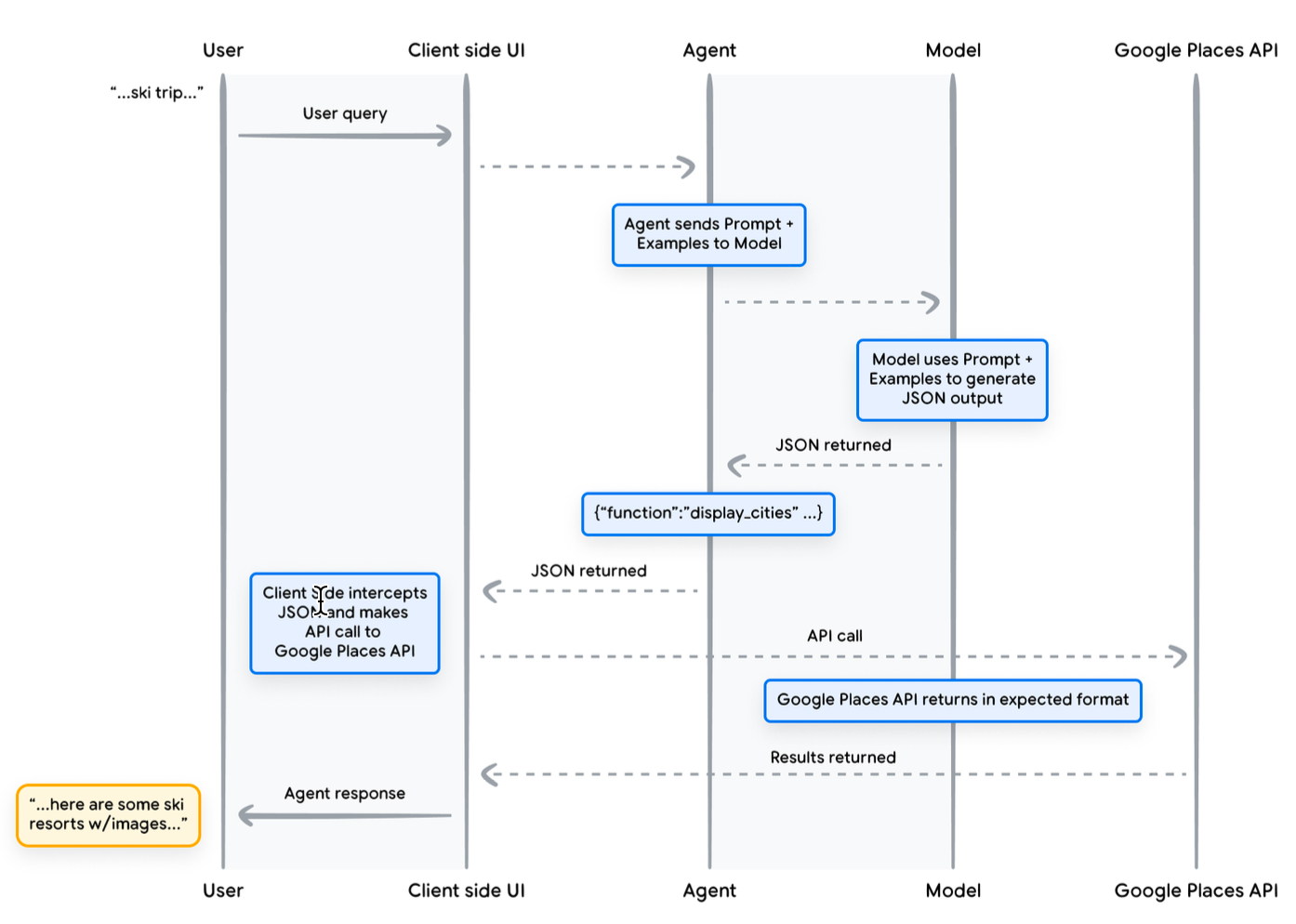
Function 示例:
# function tool
def display_cities(cities: list[str], preferences: Optional[str] = None):
"""Provides a list of cities based on the user's search query and preferences.
Args:
preferences (str): The user's preferences for the search, like skiing,
beach, restaurants, bbq, etc.
cities (list[str]): The list of cities being recommended to the user.
Returns:
list[str]: The list of cities being recommended to the user.
"""
return cities
# example calling function in Agent
from vertexai.generative_models import GenerativeModel, Tool, FunctionDeclaration
model = GenerativeModel("gemini-1.5-flash-001")
display_cities_function = FunctionDeclaration.from_func(display_cities)
tool = Tool(function_declarations=[display_cities_function])
message = "I’d like to take a ski trip with my family but I’m not sure where
to go."
res = model.generate_content(message, tools=[tool])
print(f"Function Name: {res.candidates[0].content.parts[0].function_call.name}")
print(f"Function Args: {res.candidates[0].content.parts[0].function_call.args}")
> Function Name: display_cities
> Function Args: {'preferences': 'skiing', 'cities': ['Aspen', 'Vail',
'Park City']}
Data Store
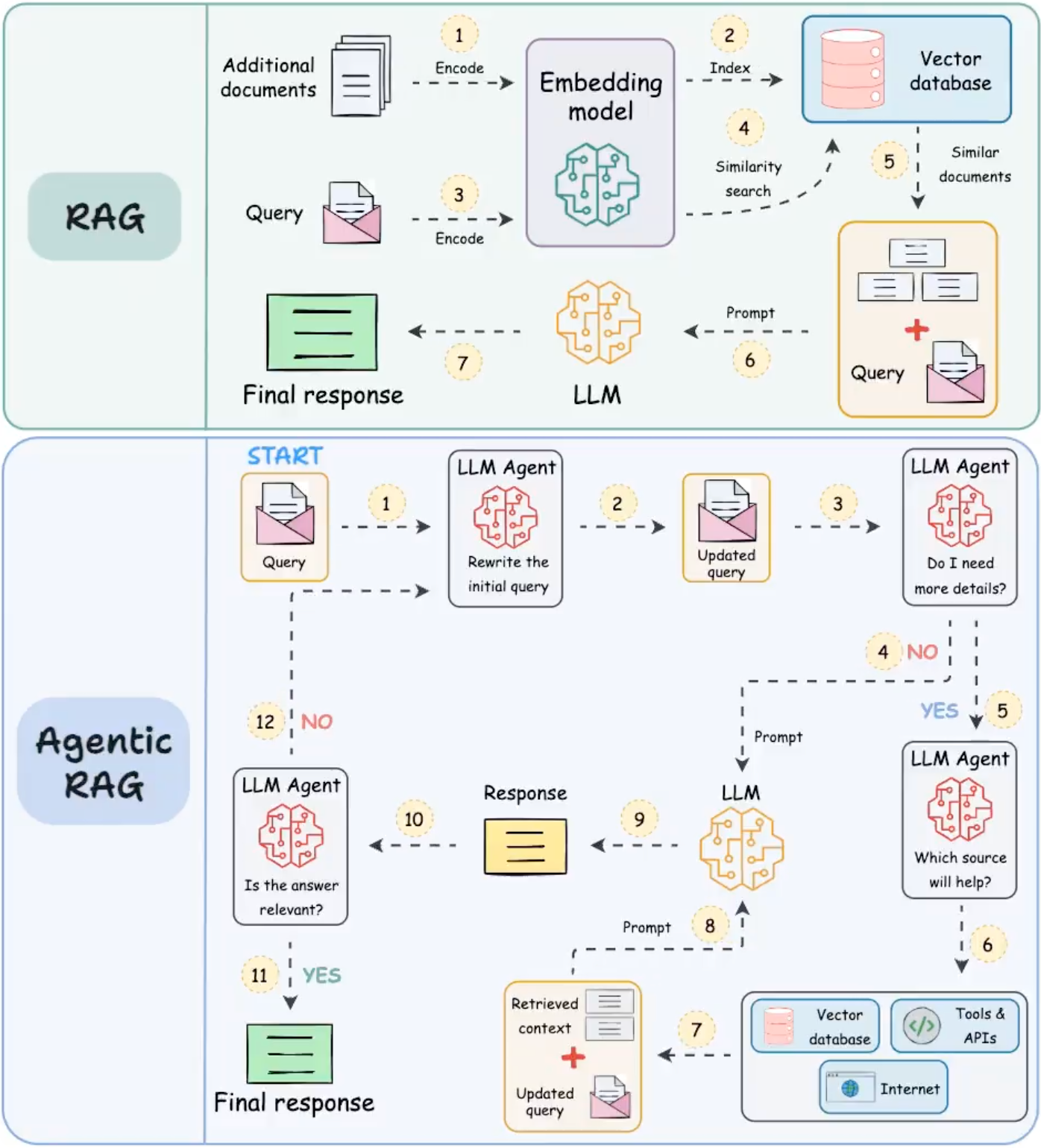
Data Store 允许开发人员以原始格式向 Agent 提供额外数据,从而无需进行耗时的数据转换、模型再训练或微调。Data Store 将传入的文档转换为一组矢量数据库嵌入,Agent 可以使用这些嵌入来提取所需的信息,以补充其下一步操作或对用户的响应。

在 AI Agent 的上下文中,Data Store 通常实现为向量数据库,开发人员希望 Agent 在运行时能够访问该数据库。虽然我们不会在这里深入介绍向量数据库,但要理解的关键点是它们以向量嵌入的形式存储数据,这是一种高维向量或所提供数据的数学表示。近年来,数据存储在语言模型中的最常见使用示例之一是实现基于检索增强生成 (RAG) 的应用程序。这些应用程序试图通过让模型访问各种格式的数据来扩展模型知识的广度和深度,使其超越基础训练数据:
- 网站内容
- PDF、Word 文档、CSV、电子表格等格式的结构化数据。
- HTML、PDF、TXT 等格式的非结构化数据。
随着 AI Agent 的迭代优化,基于 Data Store 的 RAG 技术也在更新,可以简单的看一下传统 RAG 与 Agentic RAG 的对比(后面再写专题细细研究):
Public discussion